Filecoin – Precommit2计算介绍





Sector计算的部分分为Precommit1和Precommit2两部分。两部分合在一起,称为SDR算法。
Sector计算的部分分为Precommit1和Precommit2两部分。两部分合在一起,称为SDR算法。整个SDR算法的相关计算在之前的文章介绍过: [Filecoin - 为什么SDR这么慢?](http://mp.weixin.qq.com/s?__biz=MzU5MzMxNTk2Nw==&mid=2247486980&idx=1&sn=d525f288bd1305191a7cd7a4d26acb8c&chksm=fe131f14c9649602fdb874443a0b09ead774208e3fa1ca6dc4bb35322390299aa7eeeffe2141&scene=21#wechat_redirect) 本文着重介绍一下Precommit2的计算逻辑。Precommit2计算分为两部分: 1、Column Hash计算以及Merkle树构造 2、Replica计算以及Merkle树的构造。 相关的逻辑请查看rust-fil-proofs/storage-proofs/porep/src/stacked/vanilla/proof.rs中的transform_and_replicate_layers函数。 ## 1 Column Hash计算 Column Hash计算的实现在generate_tree_c函数。具体的实现分为两个版本:CPU和GPU版本。 ``` if settings::SETTINGS.lock().unwrap().use_gpu_column_builder { Self::generate_tree_c_gpu::( layers, nodes_count, tree_count, configs, labels, ) } else { Self::generate_tree_c_cpu::( layers, nodes_count, tree_count, configs, labels, ) } ``` GPU版本的逻辑相对复杂一些,讲讲GPU的逻辑: 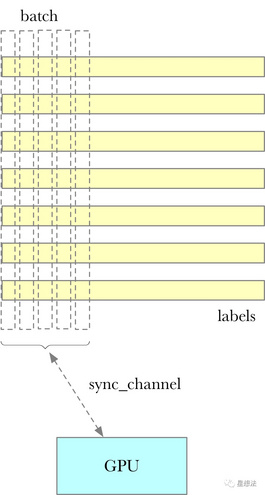 进行column计算,需要从硬盘读取11层layer的数据,并整合成column排布。GPU版本,一批批的进行处理,将一部分column读取排序后,通过channel送给GPU处理(Column Hash以及构造Merkle树)。代码逻辑大体上就是两个线程,一个读取layer的数据,column排序,另外一个GPU处理。每次batch的节点个数默认是400000,也就是135M左右。在column计算完成后,GPU构造Merkle树。 ## 2 Replica计算 Replica是最后一层layer的数据和原始数据编码之后的结果。每次Encoding一部分Replica,通过channel送给GPU(构造Merkle树)。每次batch的节点个数默认是700000,也就是22M左右。注意,batch的是Encoding的结果。 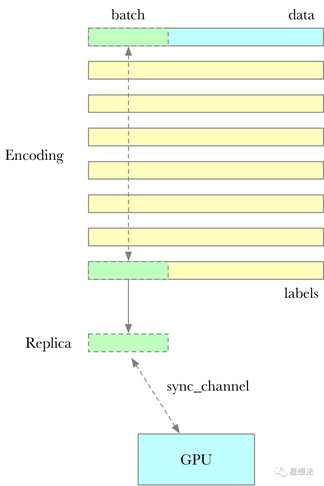 ## 3 Merkle树的构造 Merkle树的构造都是采用merkletree库。这个库实现通用的Merkle树的结构和计算。通用的Merkle树,指的是Merkle并不只是通常我们理解的二叉树,而是分成3层:top,sub和base。 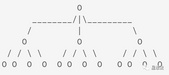 如上图的示例,top是1叉,sub是3叉,base是4叉。在Precommit2计算中,tree_c和tree_r_last都是8叉树: ``` type Tree = storage_proofs::merkle::OctMerkleTree; pub type OctMerkleTree = DiskTree; ``` ## 4 GPU加速 在Precommit2计算中,Column Hash的计算以及Merkle树的构造是采用GPU加速。相关的代码在neptune代码库中。有意思的是,这部分的代码并不是用cuda或者opencl实现的,而是一种新的更高层的语言:Futhark。 ## 5 相关宏定义 * FIL_PROOFS_USE_GPU_COLUMN_BUILDER - 使用GPU,进行column hash的计算 * FIL_PROOFS_MAX_GPU_COLUMN_BATCH_SIZE - 每次计算Column的batch大小,默认400000 * FIL_PROOFS_COLUMN_WRITE_BATCH_SIZE - 每次刷Column数据的batch大小,默认262144 * FIL_PROOFS_USE_GPU_TREE_BUILDER - 使用GPU,构造Merkle树 * FIL_PROOFS_MAX_GPU_TREE_BATCH_SIZE - 每次Encoding计算的batch大小,默认700000 **总结:** Precommit2阶段,主要是计算Column Hash以及生成Replica,并构造相应的Merkle树。其中,Column Hash的计算以及Merkle树的构造可以采用GPU加速。GPU的实现采用一种新的高层语言:Futhark。 --- 我的公众号**星想法**有很多原创高质量文章,欢迎大家扫码关注。 
Sector计算的部分分为Precommit1和Precommit2两部分。两部分合在一起,称为SDR算法。整个SDR算法的相关计算在之前的文章介绍过:
Filecoin - 为什么SDR这么慢?
本文着重介绍一下Precommit2的计算逻辑。Precommit2计算分为两部分: 1、Column Hash计算以及Merkle树构造 2、Replica计算以及Merkle树的构造。 相关的逻辑请查看rust-fil-proofs/storage-proofs/porep/src/stacked/vanilla/proof.rs中的transform_and_replicate_layers函数。
1 Column Hash计算
Column Hash计算的实现在generate_tree_c函数。具体的实现分为两个版本:CPU和GPU版本。
if settings::SETTINGS.lock().unwrap().use_gpu_column_builder {
Self::generate_tree_c_gpu::(
layers,
nodes_count,
tree_count,
configs,
labels,
)
} else {
Self::generate_tree_c_cpu::(
layers,
nodes_count,
tree_count,
configs,
labels,
)
}GPU版本的逻辑相对复杂一些,讲讲GPU的逻辑:
进行column计算,需要从硬盘读取11层layer的数据,并整合成column排布。GPU版本,一批批的进行处理,将一部分column读取排序后,通过channel送给GPU处理(Column Hash以及构造Merkle树)。代码逻辑大体上就是两个线程,一个读取layer的数据,column排序,另外一个GPU处理。每次batch的节点个数默认是400000,也就是135M左右。在column计算完成后,GPU构造Merkle树。
2 Replica计算
Replica是最后一层layer的数据和原始数据编码之后的结果。每次Encoding一部分Replica,通过channel送给GPU(构造Merkle树)。每次batch的节点个数默认是700000,也就是22M左右。注意,batch的是Encoding的结果。
3 Merkle树的构造
Merkle树的构造都是采用merkletree库。这个库实现通用的Merkle树的结构和计算。通用的Merkle树,指的是Merkle并不只是通常我们理解的二叉树,而是分成3层:top,sub和base。
如上图的示例,top是1叉,sub是3叉,base是4叉。在Precommit2计算中,tree_c和tree_r_last都是8叉树:
type Tree = storage_proofs::merkle::OctMerkleTree;
pub type OctMerkleTree = DiskTree;4 GPU加速
在Precommit2计算中,Column Hash的计算以及Merkle树的构造是采用GPU加速。相关的代码在neptune代码库中。有意思的是,这部分的代码并不是用cuda或者opencl实现的,而是一种新的更高层的语言:Futhark。
5 相关宏定义
-
FIL_PROOFS_USE_GPU_COLUMN_BUILDER - 使用GPU,进行column hash的计算
-
FIL_PROOFS_MAX_GPU_COLUMN_BATCH_SIZE - 每次计算Column的batch大小,默认400000
-
FIL_PROOFS_COLUMN_WRITE_BATCH_SIZE - 每次刷Column数据的batch大小,默认262144
-
FIL_PROOFS_USE_GPU_TREE_BUILDER - 使用GPU,构造Merkle树
-
FIL_PROOFS_MAX_GPU_TREE_BATCH_SIZE - 每次Encoding计算的batch大小,默认700000
总结:
Precommit2阶段,主要是计算Column Hash以及生成Replica,并构造相应的Merkle树。其中,Column Hash的计算以及Merkle树的构造可以采用GPU加速。GPU的实现采用一种新的高层语言:Futhark。
我的公众号星想法有很多原创高质量文章,欢迎大家扫码关注。
区块链技术网。
- 发表于 2020-06-24 09:38
- 阅读 ( 2712 )
- 学分 ( 84 )
- 分类:FileCoin




评论