在以太坊上构建 GraphQL API





如何在区块链数据之上构建一个可以轻松部署到去中心化网络基础设施的API?
> * 原文:[Building GraphQL APIs on Ethereum](https://dev.to/dabit3/building-graphql-apis-on-ethereum-4poa) 作者:Nader Dabit > * 译文出自:[登链翻译计划](https://github.com/lbc-team/Pioneer) > * 译者:[翻译小组](https://learnblockchain.cn/people/412) > * 校对:[Tiny 熊](https://learnblockchain.cn/people/15) > * 本文永久链接:[learnblockchain.cn/article…](https://learnblockchain.cn/article/2566) *接上篇[以太坊全栈开发完全指南](https://learnblockchain.cn/article/2383)* [dapp](https://ethereum.org/en/dapps/)的数量继续爆炸性增长,对开发人员([使用Solidity](https://twitter.com/CryptoCobain/status/1371901082113351680?s=20)或其他区块链语言的)的[需求](https://twitter.com/FurqanR/status/1389393957126246403?s=20)也越来越大。 作为一名[刚进入这个领域](https://twitter.com/dabit3/status/1379157277660299264)的开发人员,我很快就发现,与区块链交互和与传统网络的交互有很大的不同。在以太坊(或者其他区块链)上,数据不可以直接从其他app或前端拿来用,你需要重新组织数据并给数据建索引,以便可以有效的检索。 在传统网络上,这是数据库在中心化技术栈中所做的工作,但在[Web3栈](https://beta.web3index.org/blog/introducing-the-web3-index)中缺少索引层。 在传统的web堆栈中,数据库、服务器和api在将数据返回到应用程序(通常是通过某种http请求)之前,会对数据进行查询、筛选、排序、分页、分组和连接。但直接从以太坊或其他区块链读取数据时,这些类型的数据转换是不可能的。 过去,开发人员通过建立自己的中心化索引服务器来解决这个问题——从区块链中提取数据,存储在数据库中,然后通过API公开。这需要大量的工程和硬件资源,并破坏了去中心化的重要的安全特性。 如何在区块链数据之上构建一个可以轻松部署到去中心化网络基础设施的API?让我们来了解一下。 ## 去中心化网络基础设施 去中心化网络通常被称为[Web3](https://ethereum.org/en/developers/docs/web2-vs-web3/)。Web3在我们今天已经熟知的互联网基础上增加了这些特点: - 去中心化的 - 可验证的 - 抗审查的 - 自治的 > 想更多了解Web3,请[视频](https://www.youtube.com/watch?v=KHwVljhq7NQ) 为了实现去中心化,协议定义了提供一系列数字服务的网络,如计算、存储、带宽、身份和其他没有中介的网络基础设施。这些[协议](https://www.youtube.com/watch?v=j2rXJLW_93o)通常分布在多个节点(服务器)上,使任何希望成为网络一部分并提供服务的人都能参与。 以确保网络本身的安全性和完整性,还需要制定规则[激励](https://www.youtube.com/watch?v=Nurp3Foqf2w)网络参与者为任何消费它们的人提供最高质量的服务。这通常是通过智能合约中编写的共识机制来实现的,合约实现了各种类型的博弈论和[加密经济设计](https://thegraph.com/blog/modeling-cryptoeconomic-protocols-as-complex-systems-part-1)。 #### 什么是真正的去中心化的服务? 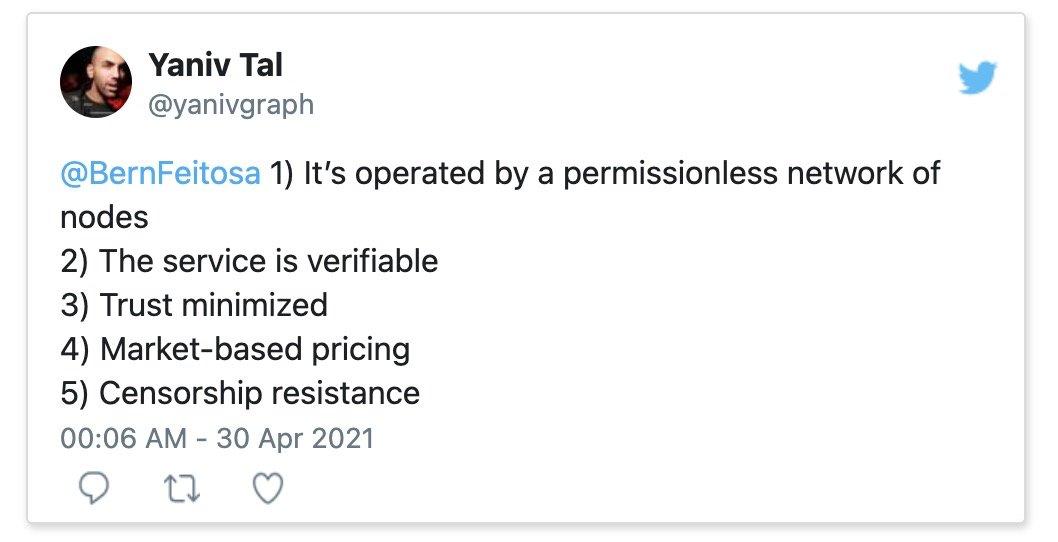 ### 构建在The Graph之上 本文中,我们将研究这样一个协议:[The Graph](https://thegraph.com/),以及如何使用存储在以太坊区块链中的数据来构建和部署自己的GraphQL API。 Graph 是一个索引协议,用于在像以太坊区块链或[IPFS](https://ipfs.io/)这样的网络上进行查询。任何人都可以建立和发布开放的API,称为subgraph —— 让数据访问变得容易。 subgraph 定义了你希望通过GraphQL API提供的数据、数据源和数据访问模式。开发者可以选择直接使用别人[已经部署](https://thegraph.com/explorer/)的subgraph,或者自己定义并部署subgraph。 开发者可以通过将他们的subgraph部署到托管服务或网络中来创建开放的API,根据其API的使用量来收费。 subgraph主要由下面几个部分组成的: #### 1.GraphQL Schema GraphQL Schema 定义了你想保存和查询的数据类型/实体。也可定义如关系或全文搜索的配置项。 #### 2.subgraph 清单( yaml 配置) [manifest](https://thegraph.com/docs/define-a-subgraph#the-subgraph-manifest)定义了subgraph索引的智能合约、合约的[ABI](https://docs.soliditylang.org/en/v0.8.4/abi-spec.html)、关注这些合约的事件,以及如何将事件数据映射到 Graph 节点存储并允许查询。 #### 3. AssemblyScript 映射 AssemblyScript 映射允许您使用 schema 中定义的实体类型保存要索引的数据。[Graph CLI](https://github.com/graphprotocol/graph-cli)还使用 schema 与智能合约的 ABI 的组合生成 AssemblyScript 类型。 ## 让我们开始构建 现在我们已经很好地理解了The Graph以及它是如何工作的,让我们开始编写一些代码。 在本教程中,我们将建立一个subgraph,用于从[Zora智能合约](https://etherscan.io/address/0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7)中查询 NTF 数据,实现获取 NFT 以及其所有者的查询,并建立它们之间的关系。 ### 安装依赖 要成功完成本教程,你的电脑上应该安装有[Node.js](https://nodejs.org/en/)。我建议使用[nvm](https://github.com/nvm-sh/nvm)或[fnm](https://github.com/Schniz/fnm/blob/master/docs/commands.md)来管理Node.js版本。 ### 在 Graph 浏览器中创建项目 首先,请打开[Graph Explorer](https://thegraph.com/explorer/dashboard),并登录或创建一个新账户。 接下来,进入[dashboard](https://thegraph.com/explorer/dashboard),点击**添加 subgraph** ,创建一个新的 subgraph。 像下面配置subgraph: - subgraph 名称 - **Zoranfts subgraph** - 副标题 - **一个用于查询 NFT 的 subgraph** - 可选 - 填写描述和 GITHUB URL 属性 subgraph 创建后,接下来我们将使用 Graph CLI 在本地初始化该 subgraph 。 ### 使用 Graph CLI 初始化一个新的 subgraph 安装Graph CLI: ``` $ npm install -g @graphprotocol/graph-cli # or $ yarn global add @graphprotocol/graph-cli ``` 当 Graph CLI 安装好后,你可以用 Graph CLI 的 `init`命令来初始化 subgraph 。 有两种方法: 1. 从一个例子 subgraph 初始化 ``` $ graph init --from-example <GITHUB_USERNAME>/<SUBGRAPH_NAME> [<DIRECTORY>] ``` 2. 从已有的智能合约初始化 如果你已经有一个智能合约部署在以太坊主网或一个测试网,从这个合约初始化一个新的 subgraph 会是一个更简单的启动和运行的方法。 ``` $ graph init --from-contract <CONTRACT_ADDRESS> \ [--network <ETHEREUM_NETWORK>] \ [--abi <FILE>] \ <GITHUB_USER>/<SUBGRAPH_NAME> [<DIRECTORY>] ``` 在本文的例子中,我们将使用[Zora Token Contract](https://etherscan.io/address/0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7#code),所以我们可以通过使用`--from-contract`标志传入合约地址,从该合约地址启动。 ``` $ graph init --from-contract 0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7 --network mainnet \ --contract-name Token --index-events ? Subgraph name › your-username/Zoranftsubgraph ? Directory to create the subgraph in › Zoranftsubgraph ? Ethereum network › Mainnet ? Contract address › 0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7 ? Contract Name · Token ``` 这个命令将根据`--from-contract`的参数(合约地址)生成一个基础的 subgraph 。通过这个合约地址,CLI 将在你的项目中初始化一些东西(包括获取 `abi` 并将它们保存在 **abis** 目录中)。 > 传入`--index-events`,CLI 将根据合约发出的事件,在**schema.graphql**和**src/mapping.ts**中自动为我们填充一些代码。 subgraph 的主要配置和定义在 **subgraph.yaml** 文件中。subgraph 的代码库由几个文件组成: - **subgraph.yaml**:一个包含 subgraph 清单的 YAML 文件 - **schema.graphql**:一个 GraphQL schema,它定义了你的 subgraph 所存储的数据,以及如何通过 GraphQL 查询它。 - **AssemblyScript 映射**。AssemblyScript 代码,将以太坊中的事件数据转换为schema 中定义的实体(例如,本教程中的 mapping.ts)。 我们要处理的 **subgraph.yaml** 条目有: - `description`(可选):对 subgraph 是什么的可读描述。当 subgraph 被部署到托管服务时,该描述将由 Graph 浏览器显示。 - `repository`(可选):可以找到 subgraph 清单的代码库的 URL。Graph 浏览器也会显示这一点。 - `dataSources.source`:subgraph 来源的智能合约的地址,以及要使用的智能合约的 ABI。地址是可选的;省略它则会在所有合约搜索匹配事件。 - `dataSources.source.startBlock`(可选):数据源开始索引的区块的编号。在大多数情况下,我们建议使用创建合约的区块。 - `dataSources.mapping.entities`:数据源写入存储的实体。每个实体的 schema 都在schema.graphql 文件中定义。 - `dataSources.mapping.abis`:一个或多个命名的 ABI 文件,用于源合约以及你在映射中与之交互的任何其他智能合约。 - `dataSources.mapping.eventHandlers`:列出该 subgraph 响应的智能合约事件和映射的处理程序--在例子中是 **./src/mapping.ts** --将这些事件转化为存储中的实体。 ### 定义实体 通过The Graph,在 **schema.graphql** 中定义实体类型,Graph Node 将生成顶层字段,用于查询该实体类型的单个实例和集合。每个成为实体的类型都需要用 `@entity` 指令来注释。 我们要索引的实体/数据是 `Token` 和 `User` 。这样,就可以对用户创建的代币以及用户本身进行索引。 要做到这一点,用以下代码更新 **schema.graphql** : ``` type Token @entity { id: ID! tokenID: BigInt! contentURI: String! metadataURI: String! creator: User! owner: User! } type User @entity { id: ID! tokens: [Token!]! @derivedFrom(field: "owner") created: [Token!]! @derivedFrom(field: "creator") } ``` ### 通过`@derivedFrom`建立关系(来自文档) 通过`@derivedFrom `字段在实体上定义反向查询,这样就在实体上创建了一个虚拟字段,使它可以被查询,但不能通过映射API手动设置。实际上,这是从另一个实体上定义的关系中衍生出来的。这样的关系,对存储关系的两者意义不大,如果只存储一方而派生另一方,则索引和查询性能都会更好。 对于一对多的关系,关系应该总是存储在 “一” 边,而 “多” 边应该总是被导出。以这种方式存储关系,而不是在 “多” 边存储一个实体数组,将使索引和查询 subgraph 的性能大大提升。一般来说,应该尽可能地避免存储实体的数组。 现在我们已经为我们的应用程序创建了 GraphQL Schema ,我们可以在本地生成实体,并开始在 CLI 创建的`mappings`中使用。 ``` graph codegen ``` 为了确保智能合约、事件和实体的工作更简单并且类型安全,Graph CLI 会从 subgraph 的 GraphQL 模式 和 数据源中包含的合约ABI 的组合中产生 AssemblyScript 类型。 ## 用实体和映射来更新subgraph 现在我们可以配置 **subgraph.yaml** 来使用刚刚创建的实体,并配置它们的映射关系。 要做到这一点,首先用 `User` 和 `Token` 实体更新 `dataSources.mapping.entities`字段。 ``` entities: - Token - User ``` 接下来,更新`dataSources.mapping.eventHandlers`,只包括以下两个事件处理程序: ``` eventHandlers: - event: TokenURIUpdated(indexed uint256,address,string) handler: handleTokenURIUpdated - event: Transfer(indexed address,indexed address,indexed uint256) handler: handleTransfer ``` 最后,更新配置,添加 `startBlock`: ``` source: address: "0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7" abi: Token startBlock: 11565020 ``` ## AssemblyScript 映射 接下来,打开 **src/mappings.ts** ,写下我们在 subgraph subgraph `eventHandlers` 中定义的映射。 用以下代码更新该文件: ``` import { TokenURIUpdated as TokenURIUpdatedEvent, Transfer as TransferEvent, Token as TokenContract } from "../generated/Token/Token" import { Token, User } from '../generated/schema' export function handleTokenURIUpdated(event: TokenURIUpdatedEvent): void { let token = Token.load(event.params._tokenId.toString()); token.contentURI = event.params._uri; token.save(); } export function handleTransfer(event: TransferEvent): void { let token = Token.load(event.params.tokenId.toString()); if (!token) { token = new Token(event.params.tokenId.toString()); token.creator = event.params.to.toHexString(); token.tokenID = event.params.tokenId; let tokenContract = TokenContract.bind(event.address); token.contentURI = tokenContract.tokenURI(event.params.tokenId); token.metadataURI = tokenContract.tokenMetadataURI(event.params.tokenId); } token.owner = event.params.to.toHexString(); token.save(); let user = User.load(event.params.to.toHexString()); if (!user) { user = new User(event.params.to.toHexString()); user.save(); } } ``` 这些映射将处理token被创建、转移或者更新时的事件。当这些事件发生时,映射将把数据保存到subgraph中。 ### 运行构建 接下来,让我们运行构建,以确保一切配置正确,运行`build`命令: ``` $ graph build ``` 如果构建成功,应该看到在你的根目录中生成了一个新的 **build** 文件夹。 ## 部署subgraph 要部署,我们可以使用 Graph CLI 运行 `deploy` 命令。要部署,首先需要为你在 Graph Explorer 中创建的 subgraph 复制 **Access token**。 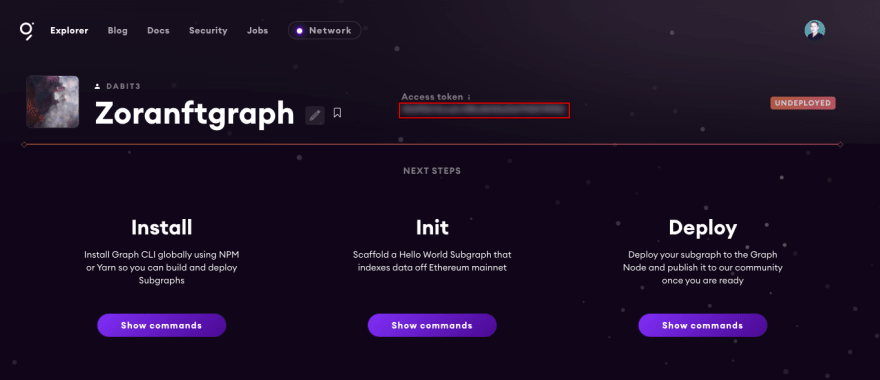 接下来,运行以下命令: ``` $ graph auth https://api.thegraph.com/deploy/ <ACCESS_TOKEN> $ yarn deploy ``` 当 subgraph 部署完毕,你可以看到它显示在你的仪表板上: 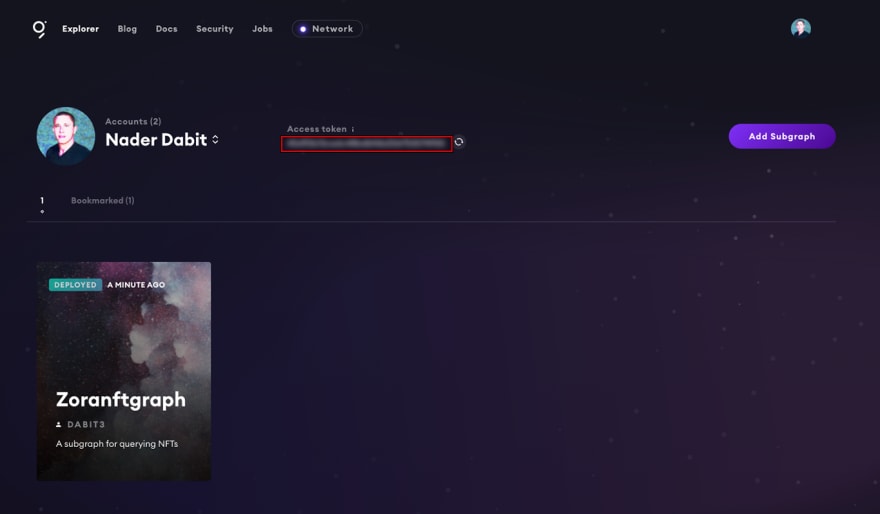 当你点击 subgraph 的时候,就会打开 Graph explorer: 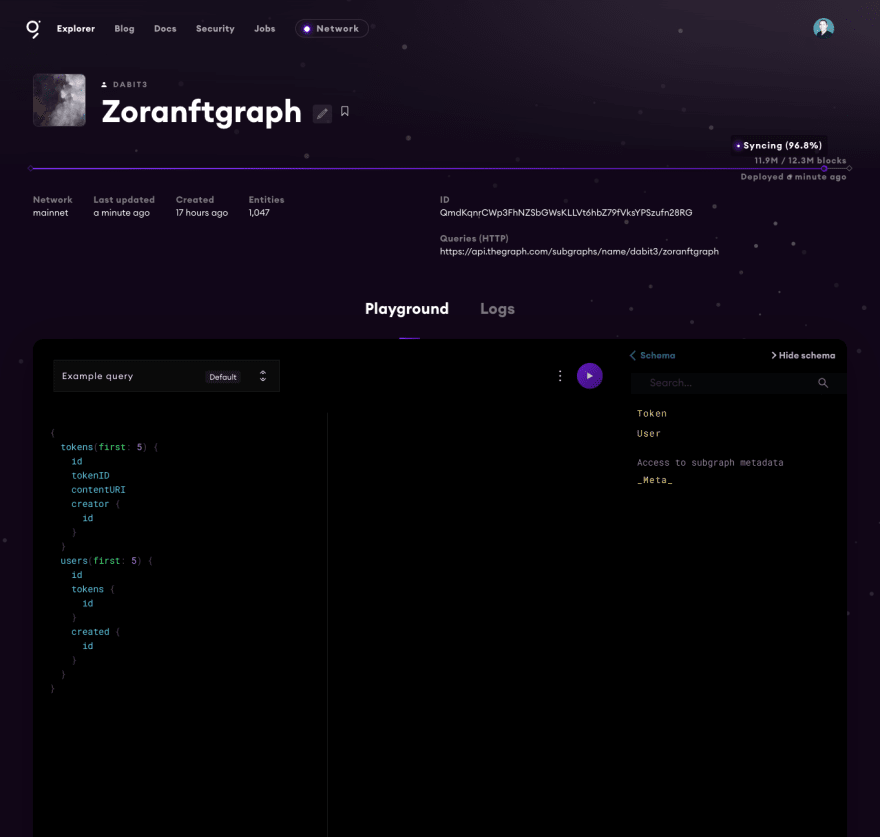 ## 查询数据 现在我们在仪表板中了,可以开始查询数据了。运行下面的查询,获得一个 token 列表和它们的元数据: ``` { tokens { id tokenID contentURI metadataURI } } ``` 我们还可以配置订单方向: ``` { tokens( orderBy:id, orderDirection: desc ) { id tokenID contentURI metadataURI } } ``` 或者选择向前跳过一定数量的结果,实现一些基本的分页: ``` { tokens( skip: 100, orderBy:id, orderDirection: desc ) { id tokenID contentURI metadataURI } } ``` 或者查询用户和他们的相关内容: ``` { users { id tokens { id contentURI } } } ``` ## 更新subgraph 如果我们想对 subgraph 做一些改变,然后重新部署,怎么办?这很容易,让我们来学习如何做。 假设我们想给我们的 subgraph 添加一个新功能。除了我们现有的查询功能外,假设我们想增加按 NFT 创建的时间戳排序的功能。 要做到这一点,我们首先需要在 `Token`实体中添加一个新的 `createdAtTimestamp ` 字段: ``` type Token @entity { id: ID! tokenID: BigInt! contentURI: String! metadataURI: String! creator: User! owner: User! "Add new createdAtTimesamp field" createdAtTimestamp: BigInt! } ``` 现在我们可以重新运行 codegen : ``` graph codegen ``` 接下来,我们需要更新映射以保存这个新字段: ``` // update the handleTransfer function to add the createdAtTimestamp to the token object export function handleTransfer(event: TransferEvent): void { let token = Token.load(event.params.tokenId.toString()); if (!token) { token = new Token(event.params.tokenId.toString()); token.creator = event.params.to.toHexString(); token.tokenID = event.params.tokenId; // Add the createdAtTimestamp to the token object token.createdAtTimestamp = event.block.timestamp; let tokenContract = TokenContract.bind(event.address); token.contentURI = tokenContract.tokenURI(event.params.tokenId); token.metadataURI = tokenContract.tokenMetadataURI(event.params.tokenId); } token.owner = event.params.to.toHexString(); token.save(); let user = User.load(event.params.to.toHexString()); if (!user) { user = new User(event.params.to.toHexString()); user.save(); } } ``` 现在我们可以重新部署 subgraph 了: ``` $ yarn deploy ``` 一旦 subgraph 被重新部署,我们就可以通过时间戳查询来查看最近创建的 NFTS。 ``` { tokens( orderBy:createdAtTimestamp, orderDirection: desc ) { id tokenID contentURI metadataURI } } ``` > 这个项目的代码库位于[这里](https://github.com/dabit3/building-a-subgraph-workshop/tree/main/Zoranftgraph) ## 接下来的步骤 如果你有兴趣了解更多关于 Web3、构建 Dapps 或构建 subgraph 的信息,请查看以下资源。 The Graph on Twitter - [@graphprotocol] (https://twitter.com/graphprotocol) [全栈式以太坊开发完整指南](https://learnblockchain.cn/article/2383) [The Graph Discord](https://thegraph.com/discord) [Solidity Docs](https://docs.soliditylang.org/) [以太坊 Developer Documentation](https://ethereum.org/en/developers/docs/) Austin Griffith on Twitter [@austingriffith](https://twitter.com/austingriffith) & [Scaffold Eth](https://github.com/austintgriffith/scaffold-eth) [Crypto Zombies](https://cryptozombies.io/) --- 本翻译由 [Cell Network](https://www.cellnetwork.io/?utm_souce=learnblockchain) 赞助支持。
- 原文:Building GraphQL APIs on Ethereum 作者:Nader Dabit
- 译文出自:登链翻译计划
- 译者:翻译小组
- 校对:Tiny 熊
- 本文永久链接:learnblockchain.cn/article…
接上篇以太坊全栈开发完全指南
dapp的数量继续爆炸性增长,对开发人员(使用Solidity或其他区块链语言的)的需求也越来越大。
作为一名刚进入这个领域的开发人员,我很快就发现,与区块链交互和与传统网络的交互有很大的不同。在以太坊(或者其他区块链)上,数据不可以直接从其他app或前端拿来用,你需要重新组织数据并给数据建索引,以便可以有效的检索。
在传统网络上,这是数据库在中心化技术栈中所做的工作,但在Web3栈中缺少索引层。
在传统的web堆栈中,数据库、服务器和api在将数据返回到应用程序(通常是通过某种http请求)之前,会对数据进行查询、筛选、排序、分页、分组和连接。但直接从以太坊或其他区块链读取数据时,这些类型的数据转换是不可能的。
过去,开发人员通过建立自己的中心化索引服务器来解决这个问题——从区块链中提取数据,存储在数据库中,然后通过API公开。这需要大量的工程和硬件资源,并破坏了去中心化的重要的安全特性。
如何在区块链数据之上构建一个可以轻松部署到去中心化网络基础设施的API?让我们来了解一下。
去中心化网络基础设施
去中心化网络通常被称为Web3。Web3在我们今天已经熟知的互联网基础上增加了这些特点:
- 去中心化的
- 可验证的
- 抗审查的
- 自治的
想更多了解Web3,请视频
为了实现去中心化,协议定义了提供一系列数字服务的网络,如计算、存储、带宽、身份和其他没有中介的网络基础设施。这些协议通常分布在多个节点(服务器)上,使任何希望成为网络一部分并提供服务的人都能参与。
以确保网络本身的安全性和完整性,还需要制定规则激励网络参与者为任何消费它们的人提供最高质量的服务。这通常是通过智能合约中编写的共识机制来实现的,合约实现了各种类型的博弈论和加密经济设计。
什么是真正的去中心化的服务?
构建在The Graph之上
本文中,我们将研究这样一个协议:The Graph,以及如何使用存储在以太坊区块链中的数据来构建和部署自己的GraphQL API。
Graph 是一个索引协议,用于在像以太坊区块链或IPFS这样的网络上进行查询。任何人都可以建立和发布开放的API,称为subgraph —— 让数据访问变得容易。
subgraph 定义了你希望通过GraphQL API提供的数据、数据源和数据访问模式。开发者可以选择直接使用别人已经部署的subgraph,或者自己定义并部署subgraph。
开发者可以通过将他们的subgraph部署到托管服务或网络中来创建开放的API,根据其API的使用量来收费。
subgraph主要由下面几个部分组成的:
1.GraphQL Schema
GraphQL Schema 定义了你想保存和查询的数据类型/实体。也可定义如关系或全文搜索的配置项。
2.subgraph 清单( yaml 配置)
manifest定义了subgraph索引的智能合约、合约的ABI、关注这些合约的事件,以及如何将事件数据映射到 Graph 节点存储并允许查询。
3. AssemblyScript 映射
AssemblyScript 映射允许您使用 schema 中定义的实体类型保存要索引的数据。Graph CLI还使用 schema 与智能合约的 ABI 的组合生成 AssemblyScript 类型。
让我们开始构建
现在我们已经很好地理解了The Graph以及它是如何工作的,让我们开始编写一些代码。
在本教程中,我们将建立一个subgraph,用于从Zora智能合约中查询 NTF 数据,实现获取 NFT 以及其所有者的查询,并建立它们之间的关系。
安装依赖
要成功完成本教程,你的电脑上应该安装有Node.js。我建议使用nvm或fnm来管理Node.js版本。
在 Graph 浏览器中创建项目
首先,请打开Graph Explorer,并登录或创建一个新账户。
接下来,进入dashboard,点击添加 subgraph ,创建一个新的 subgraph。
像下面配置subgraph:
- subgraph 名称 - Zoranfts subgraph
- 副标题 - 一个用于查询 NFT 的 subgraph
- 可选 - 填写描述和 GITHUB URL 属性
subgraph 创建后,接下来我们将使用 Graph CLI 在本地初始化该 subgraph 。
使用 Graph CLI 初始化一个新的 subgraph
安装Graph CLI:
$ npm install -g @graphprotocol/graph-cli
# or
$ yarn global add @graphprotocol/graph-cli当 Graph CLI 安装好后,你可以用 Graph CLI 的 init命令来初始化 subgraph 。
有两种方法:
- 从一个例子 subgraph 初始化
$ graph init --from-example <GITHUB_USERNAME>/<SUBGRAPH_NAME> [<DIRECTORY>]- 从已有的智能合约初始化
如果你已经有一个智能合约部署在以太坊主网或一个测试网,从这个合约初始化一个新的 subgraph 会是一个更简单的启动和运行的方法。
$ graph init --from-contract <CONTRACT_ADDRESS> \
[--network <ETHEREUM_NETWORK>] \
[--abi <FILE>] \
<GITHUB_USER>/<SUBGRAPH_NAME> [<DIRECTORY>]在本文的例子中,我们将使用Zora Token Contract,所以我们可以通过使用--from-contract标志传入合约地址,从该合约地址启动。
$ graph init --from-contract 0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7 --network mainnet \
--contract-name Token --index-events
? Subgraph name › your-username/Zoranftsubgraph
? Directory to create the subgraph in › Zoranftsubgraph
? Ethereum network › Mainnet
? Contract address › 0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7
? Contract Name · Token这个命令将根据--from-contract的参数(合约地址)生成一个基础的 subgraph 。通过这个合约地址,CLI 将在你的项目中初始化一些东西(包括获取 abi 并将它们保存在 abis 目录中)。
传入
--index-events,CLI 将根据合约发出的事件,在schema.graphql和src/mapping.ts中自动为我们填充一些代码。
subgraph 的主要配置和定义在 subgraph.yaml 文件中。subgraph 的代码库由几个文件组成:
- subgraph.yaml:一个包含 subgraph 清单的 YAML 文件
- schema.graphql:一个 GraphQL schema,它定义了你的 subgraph 所存储的数据,以及如何通过 GraphQL 查询它。
- AssemblyScript 映射。AssemblyScript 代码,将以太坊中的事件数据转换为schema 中定义的实体(例如,本教程中的 mapping.ts)。
我们要处理的 subgraph.yaml 条目有:
description(可选):对 subgraph 是什么的可读描述。当 subgraph 被部署到托管服务时,该描述将由 Graph 浏览器显示。repository(可选):可以找到 subgraph 清单的代码库的 URL。Graph 浏览器也会显示这一点。dataSources.source:subgraph 来源的智能合约的地址,以及要使用的智能合约的 ABI。地址是可选的;省略它则会在所有合约搜索匹配事件。dataSources.source.startBlock(可选):数据源开始索引的区块的编号。在大多数情况下,我们建议使用创建合约的区块。dataSources.mapping.entities:数据源写入存储的实体。每个实体的 schema 都在schema.graphql 文件中定义。dataSources.mapping.abis:一个或多个命名的 ABI 文件,用于源合约以及你在映射中与之交互的任何其他智能合约。dataSources.mapping.eventHandlers:列出该 subgraph 响应的智能合约事件和映射的处理程序--在例子中是 ./src/mapping.ts --将这些事件转化为存储中的实体。
定义实体
通过The Graph,在 schema.graphql 中定义实体类型,Graph Node 将生成顶层字段,用于查询该实体类型的单个实例和集合。每个成为实体的类型都需要用 @entity 指令来注释。
我们要索引的实体/数据是 Token 和 User 。这样,就可以对用户创建的代币以及用户本身进行索引。
要做到这一点,用以下代码更新 schema.graphql :
type Token @entity {
id: ID!
tokenID: BigInt!
contentURI: String!
metadataURI: String!
creator: User!
owner: User!
}
type User @entity {
id: ID!
tokens: [Token!]! @derivedFrom(field: "owner")
created: [Token!]! @derivedFrom(field: "creator")
}通过@derivedFrom建立关系(来自文档)
通过@derivedFrom字段在实体上定义反向查询,这样就在实体上创建了一个虚拟字段,使它可以被查询,但不能通过映射API手动设置。实际上,这是从另一个实体上定义的关系中衍生出来的。这样的关系,对存储关系的两者意义不大,如果只存储一方而派生另一方,则索引和查询性能都会更好。
对于一对多的关系,关系应该总是存储在 “一” 边,而 “多” 边应该总是被导出。以这种方式存储关系,而不是在 “多” 边存储一个实体数组,将使索引和查询 subgraph 的性能大大提升。一般来说,应该尽可能地避免存储实体的数组。
现在我们已经为我们的应用程序创建了 GraphQL Schema ,我们可以在本地生成实体,并开始在 CLI 创建的mappings中使用。
graph codegen为了确保智能合约、事件和实体的工作更简单并且类型安全,Graph CLI 会从 subgraph 的 GraphQL 模式 和 数据源中包含的合约ABI 的组合中产生 AssemblyScript 类型。
用实体和映射来更新subgraph
现在我们可以配置 subgraph.yaml 来使用刚刚创建的实体,并配置它们的映射关系。
要做到这一点,首先用 User 和 Token 实体更新 dataSources.mapping.entities字段。
entities:
- Token
- User接下来,更新dataSources.mapping.eventHandlers,只包括以下两个事件处理程序:
eventHandlers:
- event: TokenURIUpdated(indexed uint256,address,string)
handler: handleTokenURIUpdated
- event: Transfer(indexed address,indexed address,indexed uint256)
handler: handleTransfer最后,更新配置,添加 startBlock:
source:
address: "0xabEFBc9fD2F806065b4f3C237d4b59D9A97Bcac7"
abi: Token
startBlock: 11565020AssemblyScript 映射
接下来,打开 src/mappings.ts ,写下我们在 subgraph subgraph eventHandlers 中定义的映射。
用以下代码更新该文件:
import {
TokenURIUpdated as TokenURIUpdatedEvent,
Transfer as TransferEvent,
Token as TokenContract
} from "../generated/Token/Token"
import {
Token, User
} from '../generated/schema'
export function handleTokenURIUpdated(event: TokenURIUpdatedEvent): void {
let token = Token.load(event.params._tokenId.toString());
token.contentURI = event.params._uri;
token.save();
}
export function handleTransfer(event: TransferEvent): void {
let token = Token.load(event.params.tokenId.toString());
if (!token) {
token = new Token(event.params.tokenId.toString());
token.creator = event.params.to.toHexString();
token.tokenID = event.params.tokenId;
let tokenContract = TokenContract.bind(event.address);
token.contentURI = tokenContract.tokenURI(event.params.tokenId);
token.metadataURI = tokenContract.tokenMetadataURI(event.params.tokenId);
}
token.owner = event.params.to.toHexString();
token.save();
let user = User.load(event.params.to.toHexString());
if (!user) {
user = new User(event.params.to.toHexString());
user.save();
}
}这些映射将处理token被创建、转移或者更新时的事件。当这些事件发生时,映射将把数据保存到subgraph中。
运行构建
接下来,让我们运行构建,以确保一切配置正确,运行build命令:
$ graph build如果构建成功,应该看到在你的根目录中生成了一个新的 build 文件夹。
部署subgraph
要部署,我们可以使用 Graph CLI 运行 deploy 命令。要部署,首先需要为你在 Graph Explorer 中创建的 subgraph 复制 Access token。
接下来,运行以下命令:
$ graph auth https://api.thegraph.com/deploy/ <ACCESS_TOKEN>
$ yarn deploy当 subgraph 部署完毕,你可以看到它显示在你的仪表板上:
当你点击 subgraph 的时候,就会打开 Graph explorer:
查询数据
现在我们在仪表板中了,可以开始查询数据了。运行下面的查询,获得一个 token 列表和它们的元数据:
{
tokens {
id
tokenID
contentURI
metadataURI
}
}我们还可以配置订单方向:
{
tokens(
orderBy:id,
orderDirection: desc
) {
id
tokenID
contentURI
metadataURI
}
}或者选择向前跳过一定数量的结果,实现一些基本的分页:
{
tokens(
skip: 100,
orderBy:id,
orderDirection: desc
) {
id
tokenID
contentURI
metadataURI
}
}或者查询用户和他们的相关内容:
{
users {
id
tokens {
id
contentURI
}
}
}更新subgraph
如果我们想对 subgraph 做一些改变,然后重新部署,怎么办?这很容易,让我们来学习如何做。
假设我们想给我们的 subgraph 添加一个新功能。除了我们现有的查询功能外,假设我们想增加按 NFT 创建的时间戳排序的功能。
要做到这一点,我们首先需要在 Token实体中添加一个新的 createdAtTimestamp 字段:
type Token @entity {
id: ID!
tokenID: BigInt!
contentURI: String!
metadataURI: String!
creator: User!
owner: User!
"Add new createdAtTimesamp field"
createdAtTimestamp: BigInt!
}现在我们可以重新运行 codegen :
graph codegen接下来,我们需要更新映射以保存这个新字段:
// update the handleTransfer function to add the createdAtTimestamp to the token object
export function handleTransfer(event: TransferEvent): void {
let token = Token.load(event.params.tokenId.toString());
if (!token) {
token = new Token(event.params.tokenId.toString());
token.creator = event.params.to.toHexString();
token.tokenID = event.params.tokenId;
// Add the createdAtTimestamp to the token object
token.createdAtTimestamp = event.block.timestamp;
let tokenContract = TokenContract.bind(event.address);
token.contentURI = tokenContract.tokenURI(event.params.tokenId);
token.metadataURI = tokenContract.tokenMetadataURI(event.params.tokenId);
}
token.owner = event.params.to.toHexString();
token.save();
let user = User.load(event.params.to.toHexString());
if (!user) {
user = new User(event.params.to.toHexString());
user.save();
}
}现在我们可以重新部署 subgraph 了:
$ yarn deploy一旦 subgraph 被重新部署,我们就可以通过时间戳查询来查看最近创建的 NFTS。
{
tokens(
orderBy:createdAtTimestamp,
orderDirection: desc
) {
id
tokenID
contentURI
metadataURI
}
}这个项目的代码库位于这里
接下来的步骤
如果你有兴趣了解更多关于 Web3、构建 Dapps 或构建 subgraph 的信息,请查看以下资源。
The Graph on Twitter - [@graphprotocol] (https://twitter.com/graphprotocol)
全栈式以太坊开发完整指南
The Graph Discord
Solidity Docs
以太坊 Developer Documentation
Austin Griffith on Twitter @austingriffith & Scaffold Eth
Crypto Zombies
本翻译由 Cell Network 赞助支持。
区块链技术网。
- 发表于 2021-05-31 09:15
- 阅读 ( 3608 )
- 学分 ( 290 )
- 分类:以太坊






评论