【深度知识】10分钟教会你深挖以太坊数据层














深挖以太坊状态数据层,深入了解 “Patricia 字典树”数据结构背后的理论基础
在当下数据爆炸的信息时代,凭借区块链去中心化、点对点和防篡改的特性,“区块链+大数据”已成为研究的热门,可以说,区块链与大数据的结合为今后区块链应用的大规模落地奠定了基础。 那么,区块链中的数据如何存储?不同区块链数据存储机制有何异同?以以太坊为例,在本文中,MIT 孵化初创公司 TowardsBlockChain 联合创始人 vasa 详细阐述了以太坊的数据存储机制、以太坊如何存储区块链状态与交易以及以太坊和比特币在存储机制上的异同。 此外,本文将带你深入了解 “Patricia 字典树”数据结构背后的理论基础,并通过使用 Google 的 levelDB 数据库演示以太坊字典树的具体实现。 字字行文皆重点,行行代码皆干货,请往下看! 从架构设计上来说,区块链可以简单的分为三个层次: **协议层、扩展层和应用层** 。其中,协议层又可以分为存储层和网络层,它们相互独立但又不可分割。 ## **一,数据存储层中存储了什么?** 首先了解下区块链的数据存储层,什么是区块链数据存储层?它存储了什么?它需要存储哪些数据才能保障区块链系统正常工作? 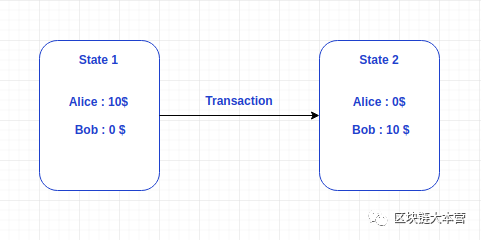 比如Alice向Bob转账10美元。从上图可以看出, **可以通过向区块链中加入一笔交易来改变区块链当前的状态** 。 在跟踪不同用户(状态)的 **账户余额** 和其他相关的细节的同时,也要跟踪不同用户通过区块链(交易)所引起的区块链 **状态转变** 的细节。 不同的区块链,比如比特币和以太坊,实现上述功能所使用的方法是不同的。 ### **1、比特币的“状态”** 比特币的“状态”由其全网络未使用的交易输出UTXO(Unspent Transaction Output)来表示。 **比特币的价值转移是通过交易来实现的** 。更具体地说,比特币用户可以通过创建一笔交易并将其一个或多个UTXO添加为交易的输入来花掉这一个或多个UTXO。 **比特币的UTXO模型,是其区别于以太坊的主要特征** ,为更好地理解二者之间的差异,先来看一些例子。 首先, **比特币中的UTXO不能只花费一部分,必须全部花完** 。 如果一个比特币用户要花费0.5个比特币,而他只有一个价值1比特币的UTXO,那么在交易时他必须将自己的比特币地址也加入到交易的输出中,即 **发给自己0.5个比特币作为找零** 。 **如果他不给自己发送找零,他将失去这0.5个比特币** ,这0.5个比特币将会被当作交易费付给挖出此区块的矿工。 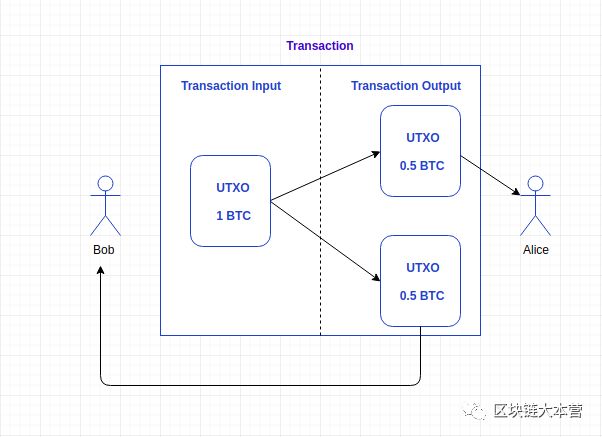 ***UTXO交易*** 其次,从本质上讲, **比特币的区块链并不会存储和更新用户的账户余额** 。在比特币网络中,用户只需持有一个或多个 UTXO 的私钥。 数字钱包的使用使得比特币的区块链看起来像是在自动存储和更新用户的帐户余额,但其实并不是这样。 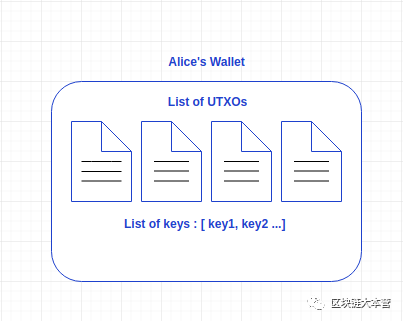 ***图解比特币钱包工作过程*** 比特币的 UTXO 模型运行良好,一部分原因是数字钱包能够执行与交易相关的大多数任务,包括但不局限于: * **处理 UTXO** * **存储密钥** * **设定交易费用** * **提供交易找零地址** * **汇总 UTXO** (显示可用的、交易进行中的和总余额) 如何来描述 UTXO 模型中的交易行为?钞票是一个绝佳的类比。 用户通过将钱包(类比比特币地址或者数字钱包)中的钞票(类比 UTXO)相加来计算自己的资金,想要花钱时,就使用一张或者多张钞票。 每张钞票只能使用一次,因为一旦花费,它就不属于你了。 因此,可以得出这样的结论: * **比特币区块链并不存储和更新账户余额** * **比特币钱包持有UTXO对应的私钥** * **如果UTXO包含在交易中,那么它会被全部花完** (在 UTXO 大于支出金额时,会收到一个全新 UTXO 的“找零”) ## **2、以太坊的“状态”** 与上述比特币的区块链不同,以太坊区块链中的状态能够 **存储和更新用户的账户余额** 等信息。 以太坊的状态不是一个抽象的概念,它是以太坊底层协议的一部分。 正如以太坊黄皮书所提到的, **以太坊是一个基于交易的“状态机”** , **是一个可以构建所有基于交易的“状态机”的技术** 。 与所有其他区块链一样,以太坊的区块链由创世区块开始延伸。 从创世区块开始,诸如 **交易,部署智能合约和挖矿** 等行为将不断改变以太坊区块链的状态。在以太坊中,每当有与该帐户相关的交易发生时,帐户余额(存储在状态字典树中)就会发生变化。 帐户余额等数据并不直接存储在以太坊区块链的区块中, 只有 **交易字典树、状态字典树和收款字典树的根节点哈希直接存储在区块链中** 。如下图: 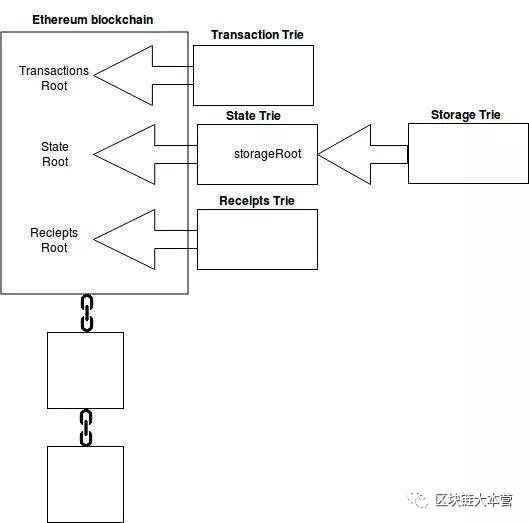 **存储字典树(保存所有智能合约数据的地方)的根节点哈希实际上指向状态字典树,而状态字典树又指向区块链。** 以太坊中存储着两种截然不同的数据: **永久数据和临时数据。** **交易信息为永久数据** ,一笔交易在得到完全确认后,将被记录在交易字典树中,它永远不会改变; **账户余额则为临时数据** ,地址对应的账户余额存储在状态字典树中,并且每当出现与该指定帐户相关的交易时账户余额就会更改。 因此,永久数据和临时数据应单独、分别存储, **以太坊使用字典树的数据结构来管理数据** 。 以太坊的记录保存机制与银行一样,一个类比就是使用ATM /借记卡。 银行跟踪每张借记卡的余额,当用户需要花钱时,银行会检查交易记录,以判断用户是否有足够的余额来进行交易。 ### **3、比特币 UTXO 模型与以太坊账户/余额模型的比较** **比特币 UTXO 模型的优点:** * **可扩展性** :由于可以同时处理多个 UTXO,因此可以实现并行交易并可促进在可扩展性上的创新。 * **隐私保护** :即使比特币不是一个完全匿名的系统,但只要用户每笔交易都使用新地址,UTXO 模型就能提供更高级别的隐私保护。如果需要增强隐私保护,可以考虑使用更复杂的方案,例如环签名。 **以太坊账户/余额模型的优点:** * **简单性** :以太坊选择了更简单直观的模型,便于开发人员实现复杂的智能合约,特别是那些需要以太坊网络状态信息或涉及多个参与方的智能合约。 比如基于以太坊网络的不同状态执行不同任务的智能合约,若使用 UTXO 的无状态模型,需要强制在每笔交易中加入状态信息,这会使智能合约的设计复杂化。 * **高效性** :除了简单性之外,以太坊账户/余额模型更加高效,因为每笔交易只需要验证发送方账户是否有足够的余额来支付交易。 **为防止以太坊账户/余额模型遭到双重支付攻击,可以用一个递增的随机数来防范这种类型的攻击。** 在以太坊中,每个帐户都有一个公共可见的随机数,每次进行交易时,这个随机数增加1,这种机制可以防止同一笔交易被多次提交。 这个随机数与以太坊工作量证明的随机数不同,后者是一个挖矿过程的随机值 **在计算机体系架构中,有时需要在不同模型之间进行折衷** 。一些区块链技术,比如 Hyperledger,就采用了 UTXO 机制,因为这样可以从比特币区块链所衍生的创新中受益。 接下来简要分析更多基于这两种记录保存模型构建的技术。 ### **以太坊字典树数据结构** 以太坊字典树数据结构主要包括状态字典树、存储字典树和交易字典树。 **1、状态字典树——独一无二的存在** 在以太坊网络中有一个 **唯一的全网络状态字典树** 。 这个全网络状态字典树不断在更新。 这个全网络状态字典树中包含 **以太坊网络中每个账户所对应的键值对** (key and value pair)。 全网络状态字典树中的“键”是一个的160位标识符(以太坊帐户的地址)。 全网络状态字典树中的“值”是通过对以太坊账户的以下详细信息进行编码(使用递归长度字典编码(Recursive-Length Prefix encoding,RLP)方法)生成的: * **Nonce** :一个公共可见的随机数。如果帐户是一个外部帐户,这个数字代表从帐户地址发送的交易数量;如果帐户是一个合约帐户,Nonce 是帐户创建的合约数量。 * **balance** :这个地址拥有的 Wei(以太坊货币单位)数量,每个以太币有1e+18 Wei。 * **storageRoot** :一个Merkle Patricia 树根节点的哈希,它对帐户的存储内容的哈希值进行编码,并默认为空。 * **codeHash** :EVM(以太坊虚拟机)的哈希值代码。 对于合约帐户,这是一个被哈希计算后并存储为codeHash的代码;对于外部帐户,codeHash字段是空字符串的哈希值。 **状态字典树的根节点(在给定时间点整个状态字典树的哈希值)被用作状态字典树的安全且唯一的标识符** ;状态字典树的根节点在密码学上取决于状态字典树所有内部的数据。 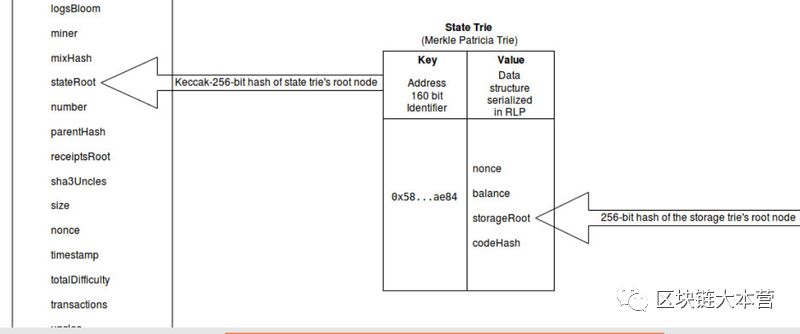 **状态字典树(Merkle Patricia 字典树的levelDB实现)和以太坊区块之间的关系**  *状态字典树:在给定的区块中,状态字典树根节点的 Keccak-256位哈希值被存储为“stateRoot”值* *stateRoot: ‘0x8c77785e3e9171715dd34117b047dffe44575c32ede59bde39fbf5dc074f2976’* ### **2、存储字典树——存储智能合约数据的地方** 存储字典树存储所有智能合约数据,每个以太坊帐户都有自己的存储字典树。存储字典树根节点的256位哈希值作为“storageRoot”值存储在全局状态字典树中。 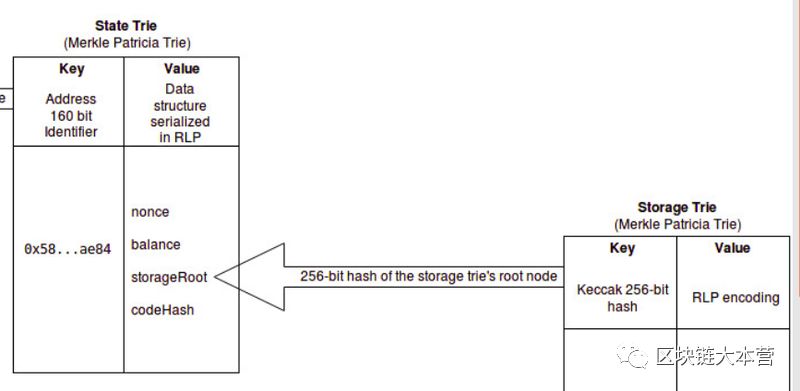 ### **3、交易字典树——每个区块一个** **每个以太坊区块都有自己独立的交易字典树。** 一个区块中包含许多交易,区块中交易的顺序由挖出该区块的矿工决定。 交易字典树中到特定交易的路径经RLP编码后得到交易在区块中的索引。 由于区块链的防篡改性,已经被挖出的区块不会再改变,所以 **区块中交易的位置永远不会改变** 。 一旦在区块的交易字典树中找到这笔交易,即使你反复返回相同的路径,检索的结果也是相同的。  ## **二,以太坊字典树实例分析** 主流的以太坊客户端使用两种不同的数据库软件解决方案来存储字典树。以太坊的 Rust 语言客户端 Parity 使用 rocksDB 数据库,而 **以太坊的 Go 语言,C ++ 语言和 Python 语言客户端都使用 levelDB 数据库** 。 本文中,主要带你了解 levelDB 数据库。 ### **1\. 以太坊和 levelDB 数据库** **LevelDB 是一个开源的谷歌键值存储程序库** ,除了常规功能外,它还提供对数据的前向和后向迭代,从字符串键到字符串值的有序映射,自定义比较函数和自动压缩。 **自动压缩功能使用开源 Google 压缩/解压缩程序库 “Snappy”** 。Snappy 程序库的设计目标并不是追求最大压缩率,而是追求非常高的压缩速度。 **LevelDB 数据库是一种重要的存储和检索机制,用于管理以太坊网络的状态。** 因此,levelDB 是主流以太坊客户端(节点),比如 go-ethereum,cpp-ethereum 和 pyethereum 的底层数据库。 虽然可以在磁盘上完成字典树数据结构的实现(使用诸如 levelDB 之类的数据库软件),但重要的是要注意遍历字典树和简单地查看键/值数据库之间存在的差异。 为了更详细说明这些差异,可以使用 Patricia 字典树的程序库来访问数据库levelDB 中的数据。 在以太坊客户端上,执行交易、部署智能合约和挖矿等网络操作,并观察它们如何影响以太坊的“状态”。 ### **2\. 分析以太坊数据库** 以太坊区块链中每个区块都包含许多 Merkle Patricia 字典树: * **状态字典树** * **存储字典树** * **交易字典树** * **收款字典树** 要在特定区块中引用特定的 Merkle Patricia 字典树,需要获取其根节点哈希值作为索引。 使用以下命令,获取创世区块中状态字典树、交易字典树和收款字典树的根节点哈希值: ``` 1web3.eth.getBlock(0).stateRoot 2web3.eth.getBlock(0).transactionsRoot 3web3.eth.getBlock(0).receiptsRoot ```  如果想得到最新挖出区块的根节点哈希(而不是创世区块),使用以下命令: ``` web3.eth.getBlock(web3.eth.blockNumber).stateRoot ``` 获取根节点哈希值之后,需要配置网络环境。 **1、安装npm、Node、Level 和 EthereumJS** 使用 **Node.js** , **Level** 和 **EthereumJS** (使用 JavaScript 语言编写的以太坊虚拟机)三个程序来进行 levelDB 数据库的实验。 通过以下命令配置实验环境。 ``` 1cd ~ 2 3sudo apt-get update 4 5sudo apt-get upgrade 6 7curl -sL https://deb.nodesource.com/setup_9.x | sudo -E bash - sudo apt-get install -y nodejs 8 9sudo apt-get install nodejs 10 11npm -v 12 13nodejs -v 14 15npm install levelup leveldown rlp merkle-patricia-tree --save 16 17git clone https://github.com/ethereumjs/ethereumjs-vm.git 18 19cd ethereumjs-vm 20 21npm install ethereumjs-account ethereumjs-util –save ``` 实验环境配置完毕后,运行以下代码将 **打印出一个以太坊帐户和对应密钥的列表** (存储在以太坊专用网络的状态根目录中), **连接以太坊的 levelDB 数据库** ,进入以太坊专用网络的状态(使用区块链中区块的 stateRoot 值),然后 **访问以太坊专用网络上所有帐户的密钥** 。 ``` 1//Just importing the requirements 2 3var Trie = require('merkle-patricia-tree/secure'); 4 5var levelup = require('levelup'); 6 7var leveldown = require('leveldown'); 8 9var RLP = require('rlp'); 10 11var assert = require('assert'); 12 13 14//Connecting to the leveldb database 15 16var db = levelup(leveldown('/home/timothymccallum/gethDataDir/geth/chaindata')); 17 18 19//Adding the "stateRoot" value from the block so that we can inspect the state root at that block height. 20 21var root = '0x8c77785e3e9171715dd34117b047dffe44575c32ede59bde39fbf5dc074f2976'; 22 23 24//Creating a trie object of the merkle-patricia-tree library 25 26var trie = new Trie(db, root); 27 28 29//Creating a nodejs stream object so that we can access the data 30 31var stream = trie.createReadStream() 32 33 34//Turning on the stream (because the node js stream is set to pause by default) 35 36stream.on('data', function (data){ 37 38 //printing out the keys of the "state trie" 39 40 console.log(data.key); 41 42}); ```  以上代码的输出 **以太坊网络中的账户只有在交易(与该特定账户相关的交易)发生时才会被加入到状态字典树中** 。 例如,仅使用命令 “ *geth account new* ” 创建的新帐户将不会被加入到状态字典树中;如果一笔成功的交易(一笔消耗了以太坊燃料并被加入到已挖出的区块中的交易)与这个账户产生关联,那么这时该账户才会出现在状态字典树里。 这可以 **防止恶意攻击者不断创建新帐户** ,从而 **维持状态字典树的正常数据量** 。 **2、解码数据** 以太坊在与 levelDB 数据库交互时使用了“ **改进的 Merkle Patricia 字典树(Modified Merkle Patricia Trie)** ”,扩展了字典树数据结构。 例如,改进的 Merkle Patricia 包含一种方法,该方法可以通过使用 **“扩展”节点** 来实现快速遍历。 在以太坊中,一个改进的的 Merkle Patricia trie 节点可以是: * **一个空字符串(NULL)** * **一个包含17个项目的数组(分支)** * **一个包含2个项目的数组(叶节点)** * **一个包含2个项目的数组(扩展名)** 由于以太坊的字典树是根据严格的规则进行设计和构建的,因此检查它们的最佳方法是使用计算机代码进行测试。 **以下示例使用了 EthereumJS** ,当提供特定区块的 stateRoot 以及以太坊帐户地址时,运行下面代码返回该帐户的余额。  *以下代码的输出(以太坊地址0xccc6b46fa5606826ce8c18fece6f519064e6130b的帐户余额)* ``` 1//Mozilla Public License 2.0 2 3//As per https://github.com/ethereumjs/ethereumjs-vm/blob/master/LICENSE 4 5//Requires the following packages to run as nodejs file https://gist.github.com/tpmccallum/0e58fc4ba9061a2e634b7a877e60143a 6 7 8//Getting the requirements 9 10var Trie = require('merkle-patricia-tree/secure'); 11 12var levelup = require('levelup'); 13 14var leveldown = require('leveldown'); 15 16var utils = require('ethereumjs-util'); 17 18var BN = utils.BN; 19 20var Account = require('ethereumjs-account'); 21 22 23//Connecting to the leveldb database 24 25var db = levelup(leveldown('/home/timothymccallum/gethDataDir/geth/chaindata')); 26 27 28//Adding the "stateRoot" value from the block so that we can inspect the state root at that block height. 29 30var root = '0x9369577baeb7c4e971ebe76f5d5daddba44c2aa42193248245cf686d20a73028'; 31 32 33//Creating a trie object of the merkle-patricia-tree library 34 35var trie = new Trie(db, root); 36 37 38var address = '0xccc6b46fa5606826ce8c18fece6f519064e6130b'; 39 40trie.get(address, function (err, raw) { 41 42 if (err) return cb(err) 43 44 //Using ethereumjs-account to create an instance of an account 45 46 var account = new Account(raw) 47 48 console.log('Account Address: ' + address); 49 50 //Using ethereumjs-util to decode and present the account balance 51 52 console.log('Balance: ' + (new BN(account.balance)).toString()); 53 54}) ``` ## **三,独特的设计带来了哪些优点?** ### **1、移动性** 如今移动设备和物联网(IoT)设备无处不在,而电子商务的未来建立在安全、强大和快速的移动应用上。  可以说区块链在移动性上取得了巨大进步,但我们也必须承认区块链大小的不断增加是不可避免的。因此 **在日常移动设备上存储整个区块链是不切实际的** 。 ### **2、速度快,不会影响安全性** 以太坊网络状态的设计及其对改进的 Merkle Patricia 字典树的使用为其应用提供了更多的可能性。 在以太坊中字典树上执行的每个操作(添加、更新或删除)都使用了确定性的密码学哈希值。 此外, **字典树根节点的密码学哈希值可以用作字典树未被篡改的证据** 。例如,对字典树数据的任何更改(例如增加 levelDB 数据库中的帐户余额)都将完全改变根节点哈希值。 这种密码学特性为轻客户端(不存储整个区块链的设备)带来了快速、可靠查询的可能性,比如 **查询账户 “0x ... 4857” 在区块高度为 “5044866” 的区块上是否有足够的资金完成此次交易等** ? “ **Merkle 证明的空间复杂度与存储数据量呈对数关系** 。这意味着,即使整个状态字典树的大小为几千兆字节,如果一个节点从受信任的源接收一个状态,该节点只需下载一个几千字节的证明数据就能够完全确定该字典树上任何信息的有效性。” ### **3、额度限制** **在以太坊白皮书中,有一个关于活期储蓄账户的概念** 。在这种情景下,两个用户(可能是丈夫和妻子,或着商业伙伴之间)每人每天最多只能提取帐户总余额的1%。 虽然这个想法仅仅在白皮书中 **“进一步发展方向”** 的部分中被提到,但无疑它会引起人们广泛的兴趣,因为理论上它可以作为以太坊底层协议的一部分(而不是被当作为第二层协议或者是第三方钱包的一部分)。 UTXO对区块链数据是不可见的,实际上比特币区块链并不存储用户的账户余额。因此, **比特币的底层协议不太可能实现任何类型的每日额度限制** 。 ### **4、消费者信心** 相信随着区块链开发者的不断努力,我们会目睹轻量级客户端的 **快速发展** ,目睹可以与区块链技术交互的安全、强大和快速的移动应用程序的 **大规模落地** 。  在电子商务领域想要实现区块链技术的落地必须 **提高速度** 、 **安全性** 和 **可用性** 。通过巧妙的设计提供优异的可用性,安全性和性能,这将 **提高消费者信心同时增加大众的采用率** 。 数据的存储机制也是当下区块链应用落地面临的一大问题,它决定了区块链的运行效率。 **只有解决有关区块链应用落地的痛点,区块链才能真正走进人们的生活,给人们带来便利!** 看到这里,相信你对以太坊的数据存储机制已有了深入的了解。 *本文转载自 [《0.166666667小时,教会你深挖以太坊数据层》](https://mp.weixin.qq.com/s/TJFlkVMtTRuWRjvnr9EX_w) ,作者 | Vasa 企业家、TowardsBlockChain 联合创始人,编译 | kou、Guoxi,版权属于原作者。*
在当下数据爆炸的信息时代,凭借区块链去中心化、点对点和防篡改的特性,“区块链+大数据”已成为研究的热门,可以说,区块链与大数据的结合为今后区块链应用的大规模落地奠定了基础。
那么,区块链中的数据如何存储?不同区块链数据存储机制有何异同?以以太坊为例,在本文中,MIT 孵化初创公司 TowardsBlockChain 联合创始人 vasa 详细阐述了以太坊的数据存储机制、以太坊如何存储区块链状态与交易以及以太坊和比特币在存储机制上的异同。
此外,本文将带你深入了解 “Patricia 字典树”数据结构背后的理论基础,并通过使用 Google 的 levelDB 数据库演示以太坊字典树的具体实现。
字字行文皆重点,行行代码皆干货,请往下看!
从架构设计上来说,区块链可以简单的分为三个层次: 协议层、扩展层和应用层 。其中,协议层又可以分为存储层和网络层,它们相互独立但又不可分割。
一,数据存储层中存储了什么?
首先了解下区块链的数据存储层,什么是区块链数据存储层?它存储了什么?它需要存储哪些数据才能保障区块链系统正常工作?
比如Alice向Bob转账10美元。从上图可以看出, 可以通过向区块链中加入一笔交易来改变区块链当前的状态 。
在跟踪不同用户(状态)的 账户余额 和其他相关的细节的同时,也要跟踪不同用户通过区块链(交易)所引起的区块链 状态转变 的细节。
不同的区块链,比如比特币和以太坊,实现上述功能所使用的方法是不同的。
1、比特币的“状态”
比特币的“状态”由其全网络未使用的交易输出UTXO(Unspent Transaction Output)来表示。 比特币的价值转移是通过交易来实现的 。更具体地说,比特币用户可以通过创建一笔交易并将其一个或多个UTXO添加为交易的输入来花掉这一个或多个UTXO。
比特币的UTXO模型,是其区别于以太坊的主要特征 ,为更好地理解二者之间的差异,先来看一些例子。
首先, 比特币中的UTXO不能只花费一部分,必须全部花完 。
如果一个比特币用户要花费0.5个比特币,而他只有一个价值1比特币的UTXO,那么在交易时他必须将自己的比特币地址也加入到交易的输出中,即 发给自己0.5个比特币作为找零 。
如果他不给自己发送找零,他将失去这0.5个比特币 ,这0.5个比特币将会被当作交易费付给挖出此区块的矿工。
UTXO交易
其次,从本质上讲, 比特币的区块链并不会存储和更新用户的账户余额 。在比特币网络中,用户只需持有一个或多个 UTXO 的私钥。
数字钱包的使用使得比特币的区块链看起来像是在自动存储和更新用户的帐户余额,但其实并不是这样。
图解比特币钱包工作过程
比特币的 UTXO 模型运行良好,一部分原因是数字钱包能够执行与交易相关的大多数任务,包括但不局限于:
-
处理 UTXO
-
存储密钥
-
设定交易费用
-
提供交易找零地址
-
汇总 UTXO (显示可用的、交易进行中的和总余额)
如何来描述 UTXO 模型中的交易行为?钞票是一个绝佳的类比。
用户通过将钱包(类比比特币地址或者数字钱包)中的钞票(类比 UTXO)相加来计算自己的资金,想要花钱时,就使用一张或者多张钞票。
每张钞票只能使用一次,因为一旦花费,它就不属于你了。
因此,可以得出这样的结论:
-
比特币区块链并不存储和更新账户余额
-
比特币钱包持有UTXO对应的私钥
-
如果UTXO包含在交易中,那么它会被全部花完 (在 UTXO 大于支出金额时,会收到一个全新 UTXO 的“找零”)
2、以太坊的“状态”
与上述比特币的区块链不同,以太坊区块链中的状态能够 存储和更新用户的账户余额 等信息。
以太坊的状态不是一个抽象的概念,它是以太坊底层协议的一部分。
正如以太坊黄皮书所提到的, 以太坊是一个基于交易的“状态机” , 是一个可以构建所有基于交易的“状态机”的技术 。
与所有其他区块链一样,以太坊的区块链由创世区块开始延伸。
从创世区块开始,诸如 交易,部署智能合约和挖矿 等行为将不断改变以太坊区块链的状态。在以太坊中,每当有与该帐户相关的交易发生时,帐户余额(存储在状态字典树中)就会发生变化。
帐户余额等数据并不直接存储在以太坊区块链的区块中, 只有 交易字典树、状态字典树和收款字典树的根节点哈希直接存储在区块链中 。如下图:
存储字典树(保存所有智能合约数据的地方)的根节点哈希实际上指向状态字典树,而状态字典树又指向区块链。
以太坊中存储着两种截然不同的数据: 永久数据和临时数据。
交易信息为永久数据 ,一笔交易在得到完全确认后,将被记录在交易字典树中,它永远不会改变; 账户余额则为临时数据 ,地址对应的账户余额存储在状态字典树中,并且每当出现与该指定帐户相关的交易时账户余额就会更改。
因此,永久数据和临时数据应单独、分别存储, 以太坊使用字典树的数据结构来管理数据 。
以太坊的记录保存机制与银行一样,一个类比就是使用ATM /借记卡。
银行跟踪每张借记卡的余额,当用户需要花钱时,银行会检查交易记录,以判断用户是否有足够的余额来进行交易。
3、比特币 UTXO 模型与以太坊账户/余额模型的比较
比特币 UTXO 模型的优点:
-
可扩展性 :由于可以同时处理多个 UTXO,因此可以实现并行交易并可促进在可扩展性上的创新。
-
隐私保护 :即使比特币不是一个完全匿名的系统,但只要用户每笔交易都使用新地址,UTXO 模型就能提供更高级别的隐私保护。如果需要增强隐私保护,可以考虑使用更复杂的方案,例如环签名。
以太坊账户/余额模型的优点:
-
简单性 :以太坊选择了更简单直观的模型,便于开发人员实现复杂的智能合约,特别是那些需要以太坊网络状态信息或涉及多个参与方的智能合约。
比如基于以太坊网络的不同状态执行不同任务的智能合约,若使用 UTXO 的无状态模型,需要强制在每笔交易中加入状态信息,这会使智能合约的设计复杂化。
-
高效性 :除了简单性之外,以太坊账户/余额模型更加高效,因为每笔交易只需要验证发送方账户是否有足够的余额来支付交易。
为防止以太坊账户/余额模型遭到双重支付攻击,可以用一个递增的随机数来防范这种类型的攻击。
在以太坊中,每个帐户都有一个公共可见的随机数,每次进行交易时,这个随机数增加1,这种机制可以防止同一笔交易被多次提交。
这个随机数与以太坊工作量证明的随机数不同,后者是一个挖矿过程的随机值
在计算机体系架构中,有时需要在不同模型之间进行折衷 。一些区块链技术,比如 Hyperledger,就采用了 UTXO 机制,因为这样可以从比特币区块链所衍生的创新中受益。
接下来简要分析更多基于这两种记录保存模型构建的技术。
以太坊字典树数据结构
以太坊字典树数据结构主要包括状态字典树、存储字典树和交易字典树。
1、状态字典树——独一无二的存在
在以太坊网络中有一个 唯一的全网络状态字典树 。
这个全网络状态字典树不断在更新。
这个全网络状态字典树中包含 以太坊网络中每个账户所对应的键值对 (key and value pair)。
全网络状态字典树中的“键”是一个的160位标识符(以太坊帐户的地址)。
全网络状态字典树中的“值”是通过对以太坊账户的以下详细信息进行编码(使用递归长度字典编码(Recursive-Length Prefix encoding,RLP)方法)生成的:
-
Nonce :一个公共可见的随机数。如果帐户是一个外部帐户,这个数字代表从帐户地址发送的交易数量;如果帐户是一个合约帐户,Nonce 是帐户创建的合约数量。
-
balance :这个地址拥有的 Wei(以太坊货币单位)数量,每个以太币有1e+18 Wei。
-
storageRoot :一个Merkle Patricia 树根节点的哈希,它对帐户的存储内容的哈希值进行编码,并默认为空。
-
codeHash :EVM(以太坊虚拟机)的哈希值代码。 对于合约帐户,这是一个被哈希计算后并存储为codeHash的代码;对于外部帐户,codeHash字段是空字符串的哈希值。
状态字典树的根节点(在给定时间点整个状态字典树的哈希值)被用作状态字典树的安全且唯一的标识符 ;状态字典树的根节点在密码学上取决于状态字典树所有内部的数据。
状态字典树(Merkle Patricia 字典树的levelDB实现)和以太坊区块之间的关系
状态字典树:在给定的区块中,状态字典树根节点的 Keccak-256位哈希值被存储为“stateRoot”值 stateRoot: ‘0x8c77785e3e9171715dd34117b047dffe44575c32ede59bde39fbf5dc074f2976’
2、存储字典树——存储智能合约数据的地方
存储字典树存储所有智能合约数据,每个以太坊帐户都有自己的存储字典树。存储字典树根节点的256位哈希值作为“storageRoot”值存储在全局状态字典树中。
3、交易字典树——每个区块一个
每个以太坊区块都有自己独立的交易字典树。
一个区块中包含许多交易,区块中交易的顺序由挖出该区块的矿工决定。
交易字典树中到特定交易的路径经RLP编码后得到交易在区块中的索引。
由于区块链的防篡改性,已经被挖出的区块不会再改变,所以 区块中交易的位置永远不会改变 。
一旦在区块的交易字典树中找到这笔交易,即使你反复返回相同的路径,检索的结果也是相同的。
二,以太坊字典树实例分析
主流的以太坊客户端使用两种不同的数据库软件解决方案来存储字典树。以太坊的 Rust 语言客户端 Parity 使用 rocksDB 数据库,而 以太坊的 Go 语言,C ++ 语言和 Python 语言客户端都使用 levelDB 数据库 。
本文中,主要带你了解 levelDB 数据库。
1. 以太坊和 levelDB 数据库
LevelDB 是一个开源的谷歌键值存储程序库 ,除了常规功能外,它还提供对数据的前向和后向迭代,从字符串键到字符串值的有序映射,自定义比较函数和自动压缩。
自动压缩功能使用开源 Google 压缩/解压缩程序库 “Snappy” 。Snappy 程序库的设计目标并不是追求最大压缩率,而是追求非常高的压缩速度。
LevelDB 数据库是一种重要的存储和检索机制,用于管理以太坊网络的状态。 因此,levelDB 是主流以太坊客户端(节点),比如 go-ethereum,cpp-ethereum 和 pyethereum 的底层数据库。
虽然可以在磁盘上完成字典树数据结构的实现(使用诸如 levelDB 之类的数据库软件),但重要的是要注意遍历字典树和简单地查看键/值数据库之间存在的差异。
为了更详细说明这些差异,可以使用 Patricia 字典树的程序库来访问数据库levelDB 中的数据。
在以太坊客户端上,执行交易、部署智能合约和挖矿等网络操作,并观察它们如何影响以太坊的“状态”。
2. 分析以太坊数据库
以太坊区块链中每个区块都包含许多 Merkle Patricia 字典树:
-
状态字典树
-
存储字典树
-
交易字典树
-
收款字典树
要在特定区块中引用特定的 Merkle Patricia 字典树,需要获取其根节点哈希值作为索引。
使用以下命令,获取创世区块中状态字典树、交易字典树和收款字典树的根节点哈希值:
1web3.eth.getBlock(0).stateRoot
2web3.eth.getBlock(0).transactionsRoot
3web3.eth.getBlock(0).receiptsRoot
如果想得到最新挖出区块的根节点哈希(而不是创世区块),使用以下命令:
web3.eth.getBlock(web3.eth.blockNumber).stateRoot
获取根节点哈希值之后,需要配置网络环境。
1、安装npm、Node、Level 和 EthereumJS
使用 Node.js , Level 和 EthereumJS (使用 JavaScript 语言编写的以太坊虚拟机)三个程序来进行 levelDB 数据库的实验。
通过以下命令配置实验环境。
1cd ~
2
3sudo apt-get update
4
5sudo apt-get upgrade
6
7curl -sL https://deb.nodesource.com/setup_9.x | sudo -E bash - sudo apt-get install -y nodejs
8
9sudo apt-get install nodejs
10
11npm -v
12
13nodejs -v
14
15npm install levelup leveldown rlp merkle-patricia-tree --save
16
17git clone https://github.com/ethereumjs/ethereumjs-vm.git
18
19cd ethereumjs-vm
20
21npm install ethereumjs-account ethereumjs-util –save
实验环境配置完毕后,运行以下代码将 打印出一个以太坊帐户和对应密钥的列表 (存储在以太坊专用网络的状态根目录中), 连接以太坊的 levelDB 数据库 ,进入以太坊专用网络的状态(使用区块链中区块的 stateRoot 值),然后 访问以太坊专用网络上所有帐户的密钥 。
1//Just importing the requirements
2
3var Trie = require('merkle-patricia-tree/secure');
4
5var levelup = require('levelup');
6
7var leveldown = require('leveldown');
8
9var RLP = require('rlp');
10
11var assert = require('assert');
12
13
14//Connecting to the leveldb database
15
16var db = levelup(leveldown('/home/timothymccallum/gethDataDir/geth/chaindata'));
17
18
19//Adding the "stateRoot" value from the block so that we can inspect the state root at that block height.
20
21var root = '0x8c77785e3e9171715dd34117b047dffe44575c32ede59bde39fbf5dc074f2976';
22
23
24//Creating a trie object of the merkle-patricia-tree library
25
26var trie = new Trie(db, root);
27
28
29//Creating a nodejs stream object so that we can access the data
30
31var stream = trie.createReadStream()
32
33
34//Turning on the stream (because the node js stream is set to pause by default)
35
36stream.on('data', function (data){
37
38 //printing out the keys of the "state trie"
39
40 console.log(data.key);
41
42});
以上代码的输出
以太坊网络中的账户只有在交易(与该特定账户相关的交易)发生时才会被加入到状态字典树中 。
例如,仅使用命令 “ geth account new ” 创建的新帐户将不会被加入到状态字典树中;如果一笔成功的交易(一笔消耗了以太坊燃料并被加入到已挖出的区块中的交易)与这个账户产生关联,那么这时该账户才会出现在状态字典树里。
这可以 防止恶意攻击者不断创建新帐户 ,从而 维持状态字典树的正常数据量 。
2、解码数据
以太坊在与 levelDB 数据库交互时使用了“ 改进的 Merkle Patricia 字典树(Modified Merkle Patricia Trie) ”,扩展了字典树数据结构。
例如,改进的 Merkle Patricia 包含一种方法,该方法可以通过使用 “扩展”节点 来实现快速遍历。
在以太坊中,一个改进的的 Merkle Patricia trie 节点可以是:
-
一个空字符串(NULL)
-
一个包含17个项目的数组(分支)
-
一个包含2个项目的数组(叶节点)
-
一个包含2个项目的数组(扩展名)
由于以太坊的字典树是根据严格的规则进行设计和构建的,因此检查它们的最佳方法是使用计算机代码进行测试。
以下示例使用了 EthereumJS ,当提供特定区块的 stateRoot 以及以太坊帐户地址时,运行下面代码返回该帐户的余额。
以下代码的输出(以太坊地址0xccc6b46fa5606826ce8c18fece6f519064e6130b的帐户余额)
1//Mozilla Public License 2.0
2
3//As per https://github.com/ethereumjs/ethereumjs-vm/blob/master/LICENSE
4
5//Requires the following packages to run as nodejs file https://gist.github.com/tpmccallum/0e58fc4ba9061a2e634b7a877e60143a
6
7
8//Getting the requirements
9
10var Trie = require('merkle-patricia-tree/secure');
11
12var levelup = require('levelup');
13
14var leveldown = require('leveldown');
15
16var utils = require('ethereumjs-util');
17
18var BN = utils.BN;
19
20var Account = require('ethereumjs-account');
21
22
23//Connecting to the leveldb database
24
25var db = levelup(leveldown('/home/timothymccallum/gethDataDir/geth/chaindata'));
26
27
28//Adding the "stateRoot" value from the block so that we can inspect the state root at that block height.
29
30var root = '0x9369577baeb7c4e971ebe76f5d5daddba44c2aa42193248245cf686d20a73028';
31
32
33//Creating a trie object of the merkle-patricia-tree library
34
35var trie = new Trie(db, root);
36
37
38var address = '0xccc6b46fa5606826ce8c18fece6f519064e6130b';
39
40trie.get(address, function (err, raw) {
41
42 if (err) return cb(err)
43
44 //Using ethereumjs-account to create an instance of an account
45
46 var account = new Account(raw)
47
48 console.log('Account Address: ' + address);
49
50 //Using ethereumjs-util to decode and present the account balance
51
52 console.log('Balance: ' + (new BN(account.balance)).toString());
53
54})
三,独特的设计带来了哪些优点?
1、移动性
如今移动设备和物联网(IoT)设备无处不在,而电子商务的未来建立在安全、强大和快速的移动应用上。
可以说区块链在移动性上取得了巨大进步,但我们也必须承认区块链大小的不断增加是不可避免的。因此 在日常移动设备上存储整个区块链是不切实际的 。
2、速度快,不会影响安全性
以太坊网络状态的设计及其对改进的 Merkle Patricia 字典树的使用为其应用提供了更多的可能性。
在以太坊中字典树上执行的每个操作(添加、更新或删除)都使用了确定性的密码学哈希值。
此外, 字典树根节点的密码学哈希值可以用作字典树未被篡改的证据 。例如,对字典树数据的任何更改(例如增加 levelDB 数据库中的帐户余额)都将完全改变根节点哈希值。
这种密码学特性为轻客户端(不存储整个区块链的设备)带来了快速、可靠查询的可能性,比如 查询账户 “0x ... 4857” 在区块高度为 “5044866” 的区块上是否有足够的资金完成此次交易等 ?
“ Merkle 证明的空间复杂度与存储数据量呈对数关系 。这意味着,即使整个状态字典树的大小为几千兆字节,如果一个节点从受信任的源接收一个状态,该节点只需下载一个几千字节的证明数据就能够完全确定该字典树上任何信息的有效性。”
3、额度限制
在以太坊白皮书中,有一个关于活期储蓄账户的概念 。在这种情景下,两个用户(可能是丈夫和妻子,或着商业伙伴之间)每人每天最多只能提取帐户总余额的1%。
虽然这个想法仅仅在白皮书中 “进一步发展方向” 的部分中被提到,但无疑它会引起人们广泛的兴趣,因为理论上它可以作为以太坊底层协议的一部分(而不是被当作为第二层协议或者是第三方钱包的一部分)。
UTXO对区块链数据是不可见的,实际上比特币区块链并不存储用户的账户余额。因此, 比特币的底层协议不太可能实现任何类型的每日额度限制 。
4、消费者信心
相信随着区块链开发者的不断努力,我们会目睹轻量级客户端的 快速发展 ,目睹可以与区块链技术交互的安全、强大和快速的移动应用程序的 大规模落地 。
在电子商务领域想要实现区块链技术的落地必须 提高速度 、 安全性 和 可用性 。通过巧妙的设计提供优异的可用性,安全性和性能,这将 提高消费者信心同时增加大众的采用率 。
数据的存储机制也是当下区块链应用落地面临的一大问题,它决定了区块链的运行效率。
只有解决有关区块链应用落地的痛点,区块链才能真正走进人们的生活,给人们带来便利!
看到这里,相信你对以太坊的数据存储机制已有了深入的了解。
本文转载自 《0.166666667小时,教会你深挖以太坊数据层》 ,作者 | Vasa 企业家、TowardsBlockChain 联合创始人,编译 | kou、Guoxi,版权属于原作者。
- 发表于 2018-08-20 13:30
- 阅读 ( 2663 )
- 学分 ( 10 )
- 分类:以太坊







评论