死磕以太坊源码分析之Ethash共识算法



死磕以太坊源码分析之Ethash共识算法
> 死磕以太坊源码分析之Ethash共识算法 > > 代码分支:https://github.com/ethereum/go-ethereum/tree/v1.9.9 ## 引言 目前以太坊中有两个共识算法的实现:`clique`和`ethash`。而`ethash`是目前以太坊主网(`Homestead`版本)的`POW`共识算法。 ## 目录结构 `ethash`模块位于以太坊项目目录下的`consensus/ethash`目录下。 - **algorithm.go** 实现了`Dagger-Hashimoto`算法的所有功能,比如生成`cache`和`dataset`、根据`Header`和`Nonce`计算挖矿哈希等。 - **api.go** 实现了供`RPC`使用的`api`方法。 - **consensus.go** 实现了以太坊共识接口的部分方法,包括`Verify`系列方法(`VerifyHeader`、`VerifySeal`等)、`Prepare`和`Finalize`、`CalcDifficulty`、`Author`、`SealHash`。 - **ethash.go** 实现了`cache`结构体和`dataset`结构体及它们各自的方法、`MakeCache`/`MakeDataset`函数、`Ethash`对象的`New`函数,和`Ethash`的内部方法。 - **sealer.go** 实现了共识接口的`Seal`方法,和`Ethash`的内部方法`mine`。这些方法实现了`ethash`的挖矿功能。 ## Ethash 设计原理 ### Ethash设计目标 以太坊设计共识算法时,期望达到三个目的: 1. 抗`ASIC`性:为算法创建专用硬件的优势应尽可能小,让普通计算机用户也能使用CPU进行开采。 - 通过内存限制来抵制(`ASIC`使用矿机内存昂贵) - 大量随机读取内存数据时计算速度就不仅仅受限于计算单元,更受限于内存的读出速度。 2. 轻客户端可验证性: 一个区块应能被轻客户端快速有效校验。 3. 矿工应该要求存储完整的区块链状态。 ### 哈希数据集 `ethash`要计算哈希,需要先有一块数据集。这块数据集较大,初始大小大约有`1G`,每隔 3 万个区块就会更新一次,且每次更新都会比之前变大`8M`左右。计算哈希的数据源就是从这块数据集中来的;而决定使用数据集中的哪些数据进行哈希计算的,才是`header`的数据和`Nonce`字段。这部分是由`Dagger`算法实现的。 #### Dagger `Dagger`算法是用来生成数据集`Dataset`的,核心的部分就是`Dataset`的生成方式和组织结构。 可以把`Dataset`想成多个`item`(**dataItem**)组成的数组,每个`item`是`64`字节的byte数组(一条哈希)。`dataset`的初始大小约为`1G`,每隔3万个区块(一个`epoch`区间)就会更新一次,且每次更新都会比之前变大`8M`左右。 `Dataset`的每个`item`是由一个缓存块(`cache`)生成的,缓存块也可以看做多个`item`(**cacheItem**)组成,缓存块占用的内存要比`dataset`小得多,它的初始大小约为`16M`。同`dataset`类似,每隔 3 万个区块就会更新一次,且每次更新都会比之前变大`128K`左右。 生成一条`dataItem`的程是:从缓存块中“随机”(这里的“随机”不是真的随机数,而是指事前不能确定,但每次计算得到的都是一样的值)选择一个`cacheItem`进行计算,得的结果参与下次计算,这个过程会循环 256 次。 缓存块是由`seed`生成的,而`seed`的值与块的高度有关。所以生成`dataset`的过程如下图所示: 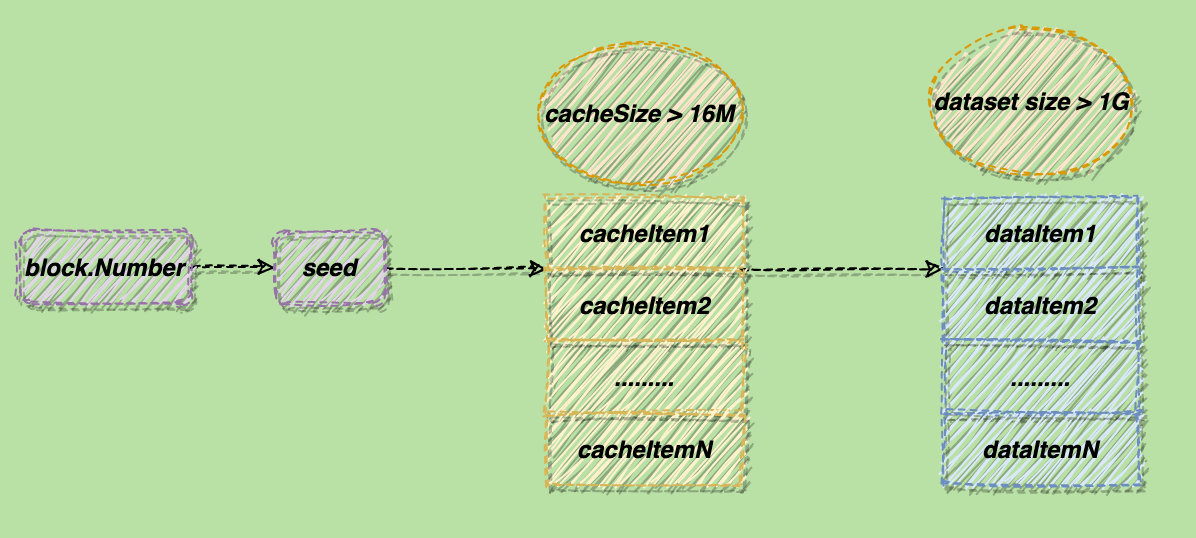 `Dagger`还有一个关键的地方,就是确定性。即同一个`epoch`内,每次计算出来的`seed`、缓存、`dataset`都是相同的。否则对于同一个区块,挖矿的人和验证的人使用不同的`dataset`,就没法进行验证了。 ----- ### Hashimoto算法 是`Thaddeus Dryja`创造的。旨在通过`IO`限制来抵制矿机。在挖矿过程中,使内存读取限制条件,由于内存设备本身会比计算设备更加便宜以及普遍,在内存升级优化方面,全世界的大公司也都投入巨大,以使内存能够适应各种用户场景,所以有了随机访问内存的概念`RAM`,因此,现有的内存可能会比较接近最优的评估算法。`Hashimoto`算法使用区块链作为源数据,满足了上面的 1 和 3 的要求。 它的作用就是使用区块Header的哈希和Nonce字段、利用dataset数据,生成一个最终的哈希值。 ------- ## 源码解析 ### 生成哈希数据集 `generate`函数位于`ethash.go`文件中,主要是为了生成`dataset`,其中包扩以下内容。 #### 生成cache size `cache size` 主要*某个特定块编号的ethash验证缓存的大小* *, `epochLength` 为 30000,如果`epoch` 小于 2048,则从已知的`epoch`返回相应的`cache size`,否则重新计算`epoch` `cache`的大小是线性增长的,`size`的值等于(2^24^ + 2^17^ * epoch - 64),用这个值除以 64 看结果是否是一个质数,如果不是,减去128 再重新计算,直到找到最大的质数为止。 ```go csize := cacheSize(d.epoch*epochLength + 1) ``` ```go func cacheSize(block uint64) uint64 { epoch := int(block / epochLength) if epoch < maxEpoch { return cacheSizes[epoch] } return calcCacheSize(epoch) } ``` ```go func calcCacheSize(epoch int) uint64 { size := cacheInitBytes + cacheGrowthBytes*uint64(epoch) - hashBytes for !new(big.Int).SetUint64(size / hashBytes).ProbablyPrime(1) { // Always accurate for n < 2^64 size -= 2 * hashBytes } return size } ``` #### 生成dataset size `dataset Size` 主要*某个特定块编号的ethash验证缓存的大小* , 类似上面生成`cache size` ```go dsize := datasetSize(d.epoch*epochLength + 1) ``` ```go func datasetSize(block uint64) uint64 { epoch := int(block / epochLength) if epoch < maxEpoch { return datasetSizes[epoch] } return calcDatasetSize(epoch) } ``` #### 生成 seed 种子 *seedHash是用于生成验证缓存和挖掘数据集的种子。*长度为 32。 ```go seed := seedHash(d.epoch*epochLength + 1) ``` ```go func seedHash(block uint64) []byte { seed := make([]byte, 32) if block < epochLength { return seed } keccak256 := makeHasher(sha3.NewLegacyKeccak256()) for i := 0; i < int(block/epochLength); i++ { keccak256(seed, seed) } return seed } ``` #### 生成cache ```go generateCache(cache, d.epoch, seed) ``` 接下来分析`generateCache`的关键代码: 先了解一下**hashBytes**,在下面的计算中都是以此为单位,它的值为 64 ,相当于一个`keccak512`哈希的长度,下文以**item**称呼`[hashBytes]byte`。 ①:初始化`cache` 此循环用来初始化`cache`:先将`seed`的哈希填入`cache`的第一个`item`,随后使用前一个`item`的哈希,填充后一个`item`。 ```go for offset := uint64(hashBytes); offset < size; offset += hashBytes { keccak512(cache[offset:], cache[offset-hashBytes:offset]) atomic.AddUint32(&progress, 1) } ``` ②:对cache中数据按规则做异或 为对于每一个`item`(`srcOff`),“随机”选一个`item`(`xorOff`)与其进行异或运算;将运算结果的哈希写入`dstOff`中。这个运算逻辑将进行`cacheRounds`次。 两个需要注意的地方: - 一是`srcOff`是从尾部向头部变化的,而`dstOff`是从头部向尾部变化的。并且它俩是对应的,即当`srcOff`代表倒数第x个item时,`dstOff`则代表正数第x个item。 - 二是`xorOff`的选取。注意我们刚才的“随机”是打了引号的。`xorOff`的值看似随机,因为在给出`seed`之前,你无法知道xorOff的值是多少;但一旦`seed`的值确定了,那么每一次`xorOff`的值都是确定的。而seed的值是由区块的高度决定的。这也是同一个`epoch`内总是能得到相同`cache`数据的原因。 ```GO for i := 0; i < cacheRounds; i++ { for j := 0; j < rows; j++ { var ( srcOff = ((j - 1 + rows) % rows) * hashBytes dstOff = j * hashBytes xorOff = (binary.LittleEndian.Uint32(cache[dstOff:]) % uint32(rows)) * hashBytes ) bitutil.XORBytes(temp, cache[srcOff:srcOff+hashBytes], cache[xorOff:xorOff+hashBytes]) keccak512(cache[dstOff:], temp) atomic.AddUint32(&progress, 1) } } ``` ------ #### 生成dataset `dataset`大小的计算和`cache`类似,量级不同:2^30^ + 2^23^ * epoch - 128,然后每次减256寻找最大质数。 生成数据是一个循环,每次生成64个字节,主要的函数是`generateDatasetItem`: `generateDatasetItem`的数据来源就是`cache`数据,而最终的dataset值会存储在mix变量中。整个过程也是由多个循环构成。 ①:初始化`mix`变量 根据cache值对`mix`变量进行初始化。其中`hashWords`代表的是一个`hash`里有多少个`word`值:一个`hash`的长度为`hashBytes`即64字节,一个`word`(uint32类型)的长度为 4 字节,因此`hashWords`值为 16。选取`cache`中的哪一项数据是由参数`index`和`i`变量决定的。 ```go mix := make([]byte, hashBytes) binary.LittleEndian.PutUint32(mix, cache[(index%rows)*hashWords]^index) for i := 1; i < hashWords; i++ { binary.LittleEndian.PutUint32(mix[i*4:], cache[(index%rows)*hashWords+uint32(i)]) } keccak512(mix, mix) ``` ②:将`mix`转换成`[]uint32`类型 ```go intMix := make([]uint32, hashWords) for i := 0; i < len(intMix); i++ { intMix[i] = binary.LittleEndian.Uint32(mix[i*4:]) } ``` ③:将`cache`数据聚合进`intmix` ```go for i := uint32(0); i < datasetParents; i++ { parent := fnv(index^i, intMix[i%16]) % rows fnvHash(intMix, cache[parent*hashWords:]) } ``` `FNV`哈希算法,是一种不需要使用密钥的哈希算法。 这个算法很简单:a乘以FNV质数0x01000193,然后再和b异或。 首先用这个算法算出一个索引值,利用这个索引从`cache`中选出一个值(`data`),然后对`mix`中的每个字节都计算一次`FNV`,得到最终的哈希值。 ```go func fnv(a, b uint32) uint32 { return a*0x01000193 ^ b } func fnvHash(mix []uint32, data []uint32) { for i := 0; i < len(mix); i++ { mix[i] = mix[i]*0x01000193 ^ data[i] } } ``` ④:将`intMix`又恢复成`mix`并计算`mix`的哈希返回 ```go for i, val := range intMix { binary.LittleEndian.PutUint32(mix[i*4:], val) } keccak512(mix, mix) return mix ``` `generateCache`和`generateDataset`是实现`Dagger`算法的核心函数,到此整个生成哈希数据集的的过程结束。 -------- ### 共识引擎核心函数 代码位于`consensus.go`  ①:`Author` ```go // 返回coinbase, coinbase是打包第一笔交易的矿工的地址 func (ethash *Ethash) Author(header *types.Header) (common.Address, error) { return header.Coinbase, nil } ``` ②:`VerifyHeader` 主要有两步检查,第一步检查**header是否已知**或者**是未知的祖先**,第二步是`ethash`的检查: 2.1 header.Extra 不能超过32字节 ```go if uint64(len(header.Extra)) > params.MaximumExtraDataSize { // 不超过32字节 return fmt.Errorf("extra-data too long: %d > %d", len(header.Extra), params.MaximumExtraDataSize) } ``` 2.2 时间戳不能超过15秒,15秒以后的就被认定为未来的块 ```go if !uncle { if header.Time > uint64(time.Now().Add(allowedFutureBlockTime).Unix()) { return consensus.ErrFutureBlock } } ``` 2.3 当前header的时间戳小于父块的 ```go if header.Time <= parent.Time { // 当前header的时间小于等于父块的 return errZeroBlockTime } ``` 2.4 根据时间戳和父块的难度来验证块的难度 ```go expected := ethash.CalcDifficulty(chain, header.Time, parent) if expected.Cmp(header.Difficulty) != 0 { return fmt.Errorf("invalid difficulty: have %v, want %v", header.Difficulty, expected) } ``` 2.5验证`gas limit`小于2^63^ -1 ```go cap := uint64(0x7fffffffffffffff) if header.GasLimit > cap { return fmt.Errorf("invalid gasLimit: have %v, max %v", header.GasLimit, cap) } ``` 2.6 确认`gasUsed`为<= `gasLimit` ```go if header.GasUsed > header.GasLimit { return fmt.Errorf("invalid gasUsed: have %d, gasLimit %d", header.GasUsed, header.GasLimit) } ``` 2.7 验证块号是父块加1 ```go if diff := new(big.Int).Sub(header.Number, parent.Number); diff.Cmp(big.NewInt(1)) != 0 { return consensus.ErrInvalidNumber } ``` 2.8检查给定的块是否满足pow难度要求 ```go if seal { if err := ethash.VerifySeal(chain, header); err != nil { return err } } ``` ③:`VerifyUncles` 3.1叔叔块最多两个 ```go if len(block.Uncles()) > maxUncles { return errTooManyUncles } ``` 3.2收集叔叔块和祖先块 ```GO number, parent := block.NumberU64()-1, block.ParentHash() for i := 0; i < 7; i++ { ancestor := chain.GetBlock(parent, number) if ancestor == nil { break } ancestors[ancestor.Hash()] = ancestor.Header() for _, uncle := range ancestor.Uncles() { uncles.Add(uncle.Hash()) } parent, number = ancestor.ParentHash(), number-1 } ancestors[block.Hash()] = block.Header() uncles.Add(block.Hash()) ``` 3.3 确保叔块只被奖励一次且叔块有个有效的祖先 ```GO for _, uncle := range block.Uncles() { // Make sure every uncle is rewarded only once hash := uncle.Hash() if uncles.Contains(hash) { return errDuplicateUncle } uncles.Add(hash) // Make sure the uncle has a valid ancestry if ancestors[hash] != nil { return errUncleIsAncestor } if ancestors[uncle.ParentHash] == nil || uncle.ParentHash == block.ParentHash() { return errDanglingUncle } if err := ethash.verifyHeader(chain, uncle, ancestors[uncle.ParentHash], true, true); err != nil { return err } ``` ④:`Prepare` > 初始化`header`的`Difficulty`字段 ```go parent := chain.GetHeader(header.ParentHash, header.Number.Uint64()-1) if parent == nil { return consensus.ErrUnknownAncestor } header.Difficulty = ethash.CalcDifficulty(chain, header.Time, parent) return nil ``` ⑤:`Finalize`会执行交易后的所有状态修改(例如,区块奖励),但**不会组装**该区块。 5.1累积任何块和叔块的奖励 ```go accumulateRewards(chain.Config(), state, header, uncles) ``` 5.2计算状态树的根哈希并提交到`header` ```go header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number)) ``` ⑥:`FinalizeAndAssemble` 运行任何交易后状态修改(例如,块奖励),并组装最终块。 ```GO func (ethash *Ethash) FinalizeAndAssemble(chain consensus.ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction, uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error) { accumulateRewards(chain.Config(), state, header, uncles) header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number)) return types.NewBlock(header, txs, uncles, receipts), nil } ``` 很明显就是比`Finalize`多了 `types.NewBlock` ⑦:`SealHash`返回在`seal`之前块的哈希(会跟`seal`之后的块哈希不同) ```go func (ethash *Ethash) SealHash(header *types.Header) (hash common.Hash) { hasher := sha3.NewLegacyKeccak256() rlp.Encode(hasher, []interface{}{ header.ParentHash, header.UncleHash, header.Coinbase, header.Root, header.TxHash, header.ReceiptHash, header.Bloom, header.Difficulty, header.Number, header.GasLimit, header.GasUsed, header.Time, header.Extra, }) hasher.Sum(hash[:0]) return hash } ``` ⑧:`Seal`给定的输入块生成一个新的密封请求(**挖矿**),并将结果推送到给定的通道中。 注意,该方法将立即返回并将异步发送结果。 根据共识算法,可能还会返回多个结果。这部分会在下面的挖矿中具体分析,这里跳过。 ------- ### 挖矿细节 > 大家在阅读本文时有任何疑问均可留言给我,我一定会及时回复。如果觉得写得不错可以关注最下方**参考**的 `github项目`,可以第一时间关注作者文章动态。 挖矿的核心接口定义: ```go Seal(chain ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error ``` 进入到`seal`函数: ①:如果运行错误的`POW`,直接返回空的`nonce`和`MixDigest`,同时块也是空块。 ```go if ethash.config.PowMode == ModeFake || ethash.config.PowMode == ModeFullFake { header := block.Header() header.Nonce, header.MixDigest = types.BlockNonce{}, common.Hash{} select { case results <- block.WithSeal(header): default: ethash.config.Log.Warn("Sealing result is not read by miner", "mode", "fake", "sealhash", ethash.SealHash(block.Header())) } return nil } ``` ②:共享`pow`的话,则转到它的共享对象执行`Seal`操作 ```go if ethash.shared != nil { return ethash.shared.Seal(chain, block, results, stop) } ``` ③:获取种子源,并根据其生成`ethash`需要的种子 ```go f ethash.rand == nil { // 获得种子 seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64)) if err != nil { ethash.lock.Unlock() return err } ethash.rand = rand.New(rand.NewSource(seed.Int64())) // 给rand赋值 } ``` ④:挖矿的核心工作交给`mine` ```go for i := 0; i < threads; i++ { pend.Add(1) go func(id int, nonce uint64) { defer pend.Done() ethash.mine(block, id, nonce, abort, locals) // 真正执行挖矿的动作 }(i, uint64(ethash.rand.Int63())) } ``` ⑤:处理挖矿的结果 - 外部意外中止,停止所有挖矿线程 - 其中一个线程挖到正确块,中止其他所有线程 - ethash对象发生改变,停止当前所有操作,重启当前方法 ```go go func() { var result *types.Block select { case <-stop: close(abort) case result = <-locals: select { case results <- result: //其中一个线程挖到正确块,中止其他所有线程 default: ethash.config.Log.Warn("Sealing result is not read by miner", "mode", "local", "sealhash", ethash.SealHash(block.Header())) } close(abort) case <-ethash.update: close(abort) if err := ethash.Seal(chain, block, results, stop); err != nil { ethash.config.Log.Error("Failed to restart sealing after update", "err", err) } } ``` 由上可以知道`seal`的核心工作是由`mine`函数完成的,重点介绍一下。 `mine`函数其实也比较简单,它是*真正的`pow`矿工,用来搜索一个`nonce`值,`nonce`值开始于`seed`值,`seed`值是能最终产生正确的可匹配可验证的区块难度* ①:从区块头中提取相关数据,放在全局变量域中 ```go var ( header = block.Header() hash = ethash.SealHash(header).Bytes() target = new(big.Int).Div(two256, header.Difficulty) // 这是用来验证的target number = header.Number.Uint64() dataset = ethash.dataset(number, false) ) ``` ②:开始产生随机`nonce`,直到我们中止或找到一个好的`nonce` ```GO var ( attempts = int64(0) nonce = seed ) ``` ③: 聚集完整的`dataset`数据,为特定的header和nonce产生最终哈希值 ```go func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) { //定义一个lookup函数,用于在数据集中查找数据 lookup := func(index uint32) []uint32 { offset := index * hashWords //hashWords是上面定义的常量值= 16 return dataset[offset : offset+hashWords] } return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup) } ``` 可以发现实际上`hashimotoFull`函数做的工作就是将原始数据集进行了读取分割,然后传给`hashimoto`函数。接下来重点分析`hashimoto`函数: 3.1根据seed获取区块头 ```go rows := uint32(size / mixBytes) ① seed := make([]byte, 40) ② copy(seed, hash) ③ binary.LittleEndian.PutUint64(seed[32:], nonce)④ seed = crypto.Keccak512(seed)⑤ seedHead := binary.LittleEndian.Uint32(seed)⑥ ``` 1. 计算数据集的行数 2. 合并`header+nonce`到一个 40 字节的`seed` 3. 将区块头的`hash`拷贝到`seed`中 4. 将`nonce`值填入`seed`的后(40-32=8)字节中去,(nonce本身就是`uint64`类型,是 64 位,对应 8 字节大小),正好把`hash`和`nonce`完整的填满了 40 字节的 seed 5. `Keccak512`加密`seed` 6. 从`seed`中获取区块头 3.2 从复制的种子开始混合 - `mixBytes`常量= 128,`mix`的长度为 32,元素为`uint32`,是 32位,对应为 4 字节大小。所以`mix`总共大小为 4*32=128 字节大小 ```go mix := make([]uint32, mixBytes/4) for i := 0; i < len(mix); i++ { mix[i] = binary.LittleEndian.Uint32(seed[i%16*4:]) } ``` 3.3 混合随机数据集节点 ```go temp := make([]uint32, len(mix))//与mix结构相同,长度相同 for i := 0; i < loopAccesses; i++ { parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows for j := uint32(0); j < mixBytes/hashBytes; j++ { copy(temp[j*hashWords:], lookup(2*parent+j)) } fnvHash(mix, temp) } ``` 3.4 压缩混合 ```go for i := 0; i < len(mix); i += 4 { mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3]) } mix = mix[:len(mix)/4] digest := make([]byte, common.HashLength) for i, val := range mix { binary.LittleEndian.PutUint32(digest[i*4:], val) } return digest, crypto.Keccak256(append(seed, digest...)) ``` 最终返回的是`digest`和`digest`与`seed`的哈希;而`digest`其实就是`mix`的`[]byte`形式。在前面`Ethash.mine`的代码中我们已经看到使用第二个返回值与`target`变量进行比较,以确定这是否是一个有效的哈希值。 ----- ### 验证pow 挖矿信息的验证有两部分: 1. 验证`Header.Difficulty`是否正确 2. 验证`Header.MixDigest`和`Header.Nonce`是否正确 ①:验证`Header.Difficulty`的代码主要在`Ethash.verifyHeader`中: ```go func (ethash *Ethash) verifyHeader(chain consensus.ChainReader, header, parent *types.Header, uncle bool, seal bool) error { ...... expected := ethash.CalcDifficulty(chain, header.Time.Uint64(), parent) if expected.Cmp(header.Difficulty) != 0 { return fmt.Errorf("invalid difficulty: have %v, want %v", header.Difficulty, expected) } } ``` 通过区块高度和时间差作为参数来计算`Difficulty`值,然后与待验证的区块的`Header.Difficulty`字段进行比较,如果相等则认为是正确的。 ②:`MixDigest`和`Nonce`的验证主要是在`Header.verifySeal`中: 验证的方式:使用`Header.Nonce`和头部哈希通过`hashimoto`重新计算一遍`MixDigest`和`result`哈希值,并且验证的节点是不需要dataset数据的。 ---- ## 总结&参考 > https://github.com/blockchainGuide > > 公众号:区块链技术栈 (推荐哦) > > https://eth.wiki/concepts/ethash/design-rationale > > https://eth.wiki/concepts/ethash/dag > > https://www.vijaypradeep.com/blog/2017-04-28-ethereums-memory-hardness-explained/
死磕以太坊源码分析之Ethash共识算法
代码分支:https://github.com/ethereum/go-ethereum/tree/v1.9.9
引言
目前以太坊中有两个共识算法的实现:clique和ethash。而ethash是目前以太坊主网(Homestead版本)的POW共识算法。
目录结构
ethash模块位于以太坊项目目录下的consensus/ethash目录下。
- algorithm.go 实现了
Dagger-Hashimoto算法的所有功能,比如生成cache和dataset、根据Header和Nonce计算挖矿哈希等。 - api.go 实现了供
RPC使用的api方法。 - consensus.go 实现了以太坊共识接口的部分方法,包括
Verify系列方法(VerifyHeader、VerifySeal等)、Prepare和Finalize、CalcDifficulty、Author、SealHash。 - ethash.go 实现了
cache结构体和dataset结构体及它们各自的方法、MakeCache/MakeDataset函数、Ethash对象的New函数,和Ethash的内部方法。 - sealer.go 实现了共识接口的
Seal方法,和Ethash的内部方法mine。这些方法实现了ethash的挖矿功能。
Ethash 设计原理
Ethash设计目标
以太坊设计共识算法时,期望达到三个目的:
- 抗
ASIC性:为算法创建专用硬件的优势应尽可能小,让普通计算机用户也能使用CPU进行开采。- 通过内存限制来抵制(
ASIC使用矿机内存昂贵) - 大量随机读取内存数据时计算速度就不仅仅受限于计算单元,更受限于内存的读出速度。
- 通过内存限制来抵制(
- 轻客户端可验证性: 一个区块应能被轻客户端快速有效校验。
- 矿工应该要求存储完整的区块链状态。
哈希数据集
ethash要计算哈希,需要先有一块数据集。这块数据集较大,初始大小大约有1G,每隔 3 万个区块就会更新一次,且每次更新都会比之前变大8M左右。计算哈希的数据源就是从这块数据集中来的;而决定使用数据集中的哪些数据进行哈希计算的,才是header的数据和Nonce字段。这部分是由Dagger算法实现的。
Dagger
Dagger算法是用来生成数据集Dataset的,核心的部分就是Dataset的生成方式和组织结构。
可以把Dataset想成多个item(dataItem)组成的数组,每个item是64字节的byte数组(一条哈希)。dataset的初始大小约为1G,每隔3万个区块(一个epoch区间)就会更新一次,且每次更新都会比之前变大8M左右。
Dataset的每个item是由一个缓存块(cache)生成的,缓存块也可以看做多个item(cacheItem)组成,缓存块占用的内存要比dataset小得多,它的初始大小约为16M。同dataset类似,每隔 3 万个区块就会更新一次,且每次更新都会比之前变大128K左右。
生成一条dataItem的程是:从缓存块中“随机”(这里的“随机”不是真的随机数,而是指事前不能确定,但每次计算得到的都是一样的值)选择一个cacheItem进行计算,得的结果参与下次计算,这个过程会循环 256 次。
缓存块是由seed生成的,而seed的值与块的高度有关。所以生成dataset的过程如下图所示:
Dagger还有一个关键的地方,就是确定性。即同一个epoch内,每次计算出来的seed、缓存、dataset都是相同的。否则对于同一个区块,挖矿的人和验证的人使用不同的dataset,就没法进行验证了。
Hashimoto算法
是Thaddeus Dryja创造的。旨在通过IO限制来抵制矿机。在挖矿过程中,使内存读取限制条件,由于内存设备本身会比计算设备更加便宜以及普遍,在内存升级优化方面,全世界的大公司也都投入巨大,以使内存能够适应各种用户场景,所以有了随机访问内存的概念RAM,因此,现有的内存可能会比较接近最优的评估算法。Hashimoto算法使用区块链作为源数据,满足了上面的 1 和 3 的要求。
它的作用就是使用区块Header的哈希和Nonce字段、利用dataset数据,生成一个最终的哈希值。
源码解析
生成哈希数据集
generate函数位于ethash.go文件中,主要是为了生成dataset,其中包扩以下内容。
生成cache size
cache size 主要某个特定块编号的ethash验证缓存的大小 *, epochLength 为 30000,如果epoch 小于 2048,则从已知的epoch返回相应的cache size,否则重新计算epoch
cache的大小是线性增长的,size的值等于(2^24^ + 2^17^ * epoch - 64),用这个值除以 64 看结果是否是一个质数,如果不是,减去128 再重新计算,直到找到最大的质数为止。
csize := cacheSize(d.epoch*epochLength + 1)func cacheSize(block uint64) uint64 {
epoch := int(block / epochLength)
if epoch < maxEpoch {
return cacheSizes[epoch]
}
return calcCacheSize(epoch)
}func calcCacheSize(epoch int) uint64 {
size := cacheInitBytes + cacheGrowthBytes*uint64(epoch) - hashBytes
for !new(big.Int).SetUint64(size / hashBytes).ProbablyPrime(1) { // Always accurate for n < 2^64
size -= 2 * hashBytes
}
return size
}生成dataset size
dataset Size 主要某个特定块编号的ethash验证缓存的大小 , 类似上面生成cache size
dsize := datasetSize(d.epoch*epochLength + 1)func datasetSize(block uint64) uint64 {
epoch := int(block / epochLength)
if epoch < maxEpoch {
return datasetSizes[epoch]
}
return calcDatasetSize(epoch)
}生成 seed 种子
seedHash是用于生成验证缓存和挖掘数据集的种子。长度为 32。
seed := seedHash(d.epoch*epochLength + 1)func seedHash(block uint64) []byte {
seed := make([]byte, 32)
if block < epochLength {
return seed
}
keccak256 := makeHasher(sha3.NewLegacyKeccak256())
for i := 0; i < int(block/epochLength); i++ {
keccak256(seed, seed)
}
return seed
}生成cache
generateCache(cache, d.epoch, seed)接下来分析generateCache的关键代码:
先了解一下hashBytes,在下面的计算中都是以此为单位,它的值为 64 ,相当于一个keccak512哈希的长度,下文以item称呼[hashBytes]byte。
①:初始化cache
此循环用来初始化cache:先将seed的哈希填入cache的第一个item,随后使用前一个item的哈希,填充后一个item。
for offset := uint64(hashBytes); offset < size; offset += hashBytes {
keccak512(cache[offset:], cache[offset-hashBytes:offset])
atomic.AddUint32(&progress, 1)
}②:对cache中数据按规则做异或
为对于每一个item(srcOff),“随机”选一个item(xorOff)与其进行异或运算;将运算结果的哈希写入dstOff中。这个运算逻辑将进行cacheRounds次。
两个需要注意的地方:
- 一是
srcOff是从尾部向头部变化的,而dstOff是从头部向尾部变化的。并且它俩是对应的,即当srcOff代表倒数第x个item时,dstOff则代表正数第x个item。 - 二是
xorOff的选取。注意我们刚才的“随机”是打了引号的。xorOff的值看似随机,因为在给出seed之前,你无法知道xorOff的值是多少;但一旦seed的值确定了,那么每一次xorOff的值都是确定的。而seed的值是由区块的高度决定的。这也是同一个epoch内总是能得到相同cache数据的原因。
for i := 0; i < cacheRounds; i++ {
for j := 0; j < rows; j++ {
var (
srcOff = ((j - 1 + rows) % rows) * hashBytes
dstOff = j * hashBytes
xorOff = (binary.LittleEndian.Uint32(cache[dstOff:]) % uint32(rows)) * hashBytes
)
bitutil.XORBytes(temp, cache[srcOff:srcOff+hashBytes], cache[xorOff:xorOff+hashBytes])
keccak512(cache[dstOff:], temp)
atomic.AddUint32(&progress, 1)
}
}生成dataset
dataset大小的计算和cache类似,量级不同:2^30^ + 2^23^ * epoch - 128,然后每次减256寻找最大质数。
生成数据是一个循环,每次生成64个字节,主要的函数是generateDatasetItem:
generateDatasetItem的数据来源就是cache数据,而最终的dataset值会存储在mix变量中。整个过程也是由多个循环构成。
①:初始化mix变量
根据cache值对mix变量进行初始化。其中hashWords代表的是一个hash里有多少个word值:一个hash的长度为hashBytes即64字节,一个word(uint32类型)的长度为 4 字节,因此hashWords值为 16。选取cache中的哪一项数据是由参数index和i变量决定的。
mix := make([]byte, hashBytes)
binary.LittleEndian.PutUint32(mix, cache[(index%rows)*hashWords]^index)
for i := 1; i < hashWords; i++ {
binary.LittleEndian.PutUint32(mix[i*4:], cache[(index%rows)*hashWords+uint32(i)])
}
keccak512(mix, mix)②:将mix转换成[]uint32类型
intMix := make([]uint32, hashWords)
for i := 0; i < len(intMix); i++ {
intMix[i] = binary.LittleEndian.Uint32(mix[i*4:])
}③:将cache数据聚合进intmix
for i := uint32(0); i < datasetParents; i++ {
parent := fnv(index^i, intMix[i%16]) % rows
fnvHash(intMix, cache[parent*hashWords:])
}FNV哈希算法,是一种不需要使用密钥的哈希算法。
这个算法很简单:a乘以FNV质数0x01000193,然后再和b异或。
首先用这个算法算出一个索引值,利用这个索引从cache中选出一个值(data),然后对mix中的每个字节都计算一次FNV,得到最终的哈希值。
func fnv(a, b uint32) uint32 {
return a*0x01000193 ^ b
}
func fnvHash(mix []uint32, data []uint32) {
for i := 0; i < len(mix); i++ {
mix[i] = mix[i]*0x01000193 ^ data[i]
}
}④:将intMix又恢复成mix并计算mix的哈希返回
for i, val := range intMix {
binary.LittleEndian.PutUint32(mix[i*4:], val)
}
keccak512(mix, mix)
return mixgenerateCache和generateDataset是实现Dagger算法的核心函数,到此整个生成哈希数据集的的过程结束。
共识引擎核心函数
代码位于consensus.go
①:Author
// 返回coinbase, coinbase是打包第一笔交易的矿工的地址
func (ethash *Ethash) Author(header *types.Header) (common.Address, error) {
return header.Coinbase, nil
}②:VerifyHeader
主要有两步检查,第一步检查header是否已知或者是未知的祖先,第二步是ethash的检查:
2.1 header.Extra 不能超过32字节
if uint64(len(header.Extra)) > params.MaximumExtraDataSize { // 不超过32字节
return fmt.Errorf("extra-data too long: %d > %d", len(header.Extra), params.MaximumExtraDataSize)
}2.2 时间戳不能超过15秒,15秒以后的就被认定为未来的块
if !uncle {
if header.Time > uint64(time.Now().Add(allowedFutureBlockTime).Unix()) {
return consensus.ErrFutureBlock
}
}2.3 当前header的时间戳小于父块的
if header.Time <= parent.Time { // 当前header的时间小于等于父块的
return errZeroBlockTime
}2.4 根据时间戳和父块的难度来验证块的难度
expected := ethash.CalcDifficulty(chain, header.Time, parent)
if expected.Cmp(header.Difficulty) != 0 {
return fmt.Errorf("invalid difficulty: have %v, want %v", header.Difficulty, expected)
}2.5验证gas limit小于2^63^ -1
cap := uint64(0x7fffffffffffffff)
if header.GasLimit > cap {
return fmt.Errorf("invalid gasLimit: have %v, max %v", header.GasLimit, cap)
}2.6 确认gasUsed为<= gasLimit
if header.GasUsed > header.GasLimit {
return fmt.Errorf("invalid gasUsed: have %d, gasLimit %d", header.GasUsed, header.GasLimit)
}2.7 验证块号是父块加1
if diff := new(big.Int).Sub(header.Number, parent.Number); diff.Cmp(big.NewInt(1)) != 0 {
return consensus.ErrInvalidNumber
}2.8检查给定的块是否满足pow难度要求
if seal {
if err := ethash.VerifySeal(chain, header); err != nil {
return err
}
}③:VerifyUncles
3.1叔叔块最多两个
if len(block.Uncles()) > maxUncles {
return errTooManyUncles
}3.2收集叔叔块和祖先块
number, parent := block.NumberU64()-1, block.ParentHash()
for i := 0; i < 7; i++ {
ancestor := chain.GetBlock(parent, number)
if ancestor == nil {
break
}
ancestors[ancestor.Hash()] = ancestor.Header()
for _, uncle := range ancestor.Uncles() {
uncles.Add(uncle.Hash())
}
parent, number = ancestor.ParentHash(), number-1
}
ancestors[block.Hash()] = block.Header()
uncles.Add(block.Hash())
3.3 确保叔块只被奖励一次且叔块有个有效的祖先
for _, uncle := range block.Uncles() {
// Make sure every uncle is rewarded only once
hash := uncle.Hash()
if uncles.Contains(hash) {
return errDuplicateUncle
}
uncles.Add(hash)
// Make sure the uncle has a valid ancestry
if ancestors[hash] != nil {
return errUncleIsAncestor
}
if ancestors[uncle.ParentHash] == nil || uncle.ParentHash == block.ParentHash() {
return errDanglingUncle
}
if err := ethash.verifyHeader(chain, uncle, ancestors[uncle.ParentHash], true, true); err != nil {
return err
}④:Prepare
初始化
header的Difficulty字段
parent := chain.GetHeader(header.ParentHash, header.Number.Uint64()-1)
if parent == nil {
return consensus.ErrUnknownAncestor
}
header.Difficulty = ethash.CalcDifficulty(chain, header.Time, parent)
return nil⑤:Finalize会执行交易后的所有状态修改(例如,区块奖励),但不会组装该区块。
5.1累积任何块和叔块的奖励
accumulateRewards(chain.Config(), state, header, uncles)5.2计算状态树的根哈希并提交到header
header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number))⑥:FinalizeAndAssemble 运行任何交易后状态修改(例如,块奖励),并组装最终块。
func (ethash *Ethash) FinalizeAndAssemble(chain consensus.ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction, uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error) {
accumulateRewards(chain.Config(), state, header, uncles)
header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number))
return types.NewBlock(header, txs, uncles, receipts), nil
}很明显就是比Finalize多了 types.NewBlock
⑦:SealHash返回在seal之前块的哈希(会跟seal之后的块哈希不同)
func (ethash *Ethash) SealHash(header *types.Header) (hash common.Hash) {
hasher := sha3.NewLegacyKeccak256()
rlp.Encode(hasher, []interface{}{
header.ParentHash,
header.UncleHash,
header.Coinbase,
header.Root,
header.TxHash,
header.ReceiptHash,
header.Bloom,
header.Difficulty,
header.Number,
header.GasLimit,
header.GasUsed,
header.Time,
header.Extra,
})
hasher.Sum(hash[:0])
return hash
}⑧:Seal给定的输入块生成一个新的密封请求(挖矿),并将结果推送到给定的通道中。
注意,该方法将立即返回并将异步发送结果。 根据共识算法,可能还会返回多个结果。这部分会在下面的挖矿中具体分析,这里跳过。
挖矿细节
大家在阅读本文时有任何疑问均可留言给我,我一定会及时回复。如果觉得写得不错可以关注最下方参考的
github项目,可以第一时间关注作者文章动态。
挖矿的核心接口定义:
Seal(chain ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error进入到seal函数:
①:如果运行错误的POW,直接返回空的nonce和MixDigest,同时块也是空块。
if ethash.config.PowMode == ModeFake || ethash.config.PowMode == ModeFullFake {
header := block.Header()
header.Nonce, header.MixDigest = types.BlockNonce{}, common.Hash{}
select {
case results <- block.WithSeal(header):
default:
ethash.config.Log.Warn("Sealing result is not read by miner", "mode", "fake", "sealhash", ethash.SealHash(block.Header()))
}
return nil
}②:共享pow的话,则转到它的共享对象执行Seal操作
if ethash.shared != nil {
return ethash.shared.Seal(chain, block, results, stop)
}③:获取种子源,并根据其生成ethash需要的种子
f ethash.rand == nil {
// 获得种子
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {
ethash.lock.Unlock()
return err
}
ethash.rand = rand.New(rand.NewSource(seed.Int64())) // 给rand赋值
}④:挖矿的核心工作交给mine
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) {
defer pend.Done()
ethash.mine(block, id, nonce, abort, locals) // 真正执行挖矿的动作
}(i, uint64(ethash.rand.Int63()))
}⑤:处理挖矿的结果
- 外部意外中止,停止所有挖矿线程
- 其中一个线程挖到正确块,中止其他所有线程
- ethash对象发生改变,停止当前所有操作,重启当前方法
go func() {
var result *types.Block
select {
case <-stop:
close(abort)
case result = <-locals:
select {
case results <- result: //其中一个线程挖到正确块,中止其他所有线程
default:
ethash.config.Log.Warn("Sealing result is not read by miner", "mode", "local", "sealhash", ethash.SealHash(block.Header()))
}
close(abort)
case <-ethash.update:
close(abort)
if err := ethash.Seal(chain, block, results, stop); err != nil {
ethash.config.Log.Error("Failed to restart sealing after update", "err", err)
}
}由上可以知道seal的核心工作是由mine函数完成的,重点介绍一下。
mine函数其实也比较简单,它是真正的pow矿工,用来搜索一个nonce值,nonce值开始于seed值,seed值是能最终产生正确的可匹配可验证的区块难度
①:从区块头中提取相关数据,放在全局变量域中
var (
header = block.Header()
hash = ethash.SealHash(header).Bytes()
target = new(big.Int).Div(two256, header.Difficulty) // 这是用来验证的target
number = header.Number.Uint64()
dataset = ethash.dataset(number, false)
)②:开始产生随机nonce,直到我们中止或找到一个好的nonce
var (
attempts = int64(0)
nonce = seed
)③: 聚集完整的dataset数据,为特定的header和nonce产生最终哈希值
func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
//定义一个lookup函数,用于在数据集中查找数据
lookup := func(index uint32) []uint32 {
offset := index * hashWords //hashWords是上面定义的常量值= 16
return dataset[offset : offset+hashWords]
}
return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup)
}可以发现实际上hashimotoFull函数做的工作就是将原始数据集进行了读取分割,然后传给hashimoto函数。接下来重点分析hashimoto函数:
3.1根据seed获取区块头
rows := uint32(size / mixBytes) ①
seed := make([]byte, 40) ②
copy(seed, hash) ③
binary.LittleEndian.PutUint64(seed[32:], nonce)④
seed = crypto.Keccak512(seed)⑤
seedHead := binary.LittleEndian.Uint32(seed)⑥- 计算数据集的行数
- 合并
header+nonce到一个 40 字节的seed - 将区块头的
hash拷贝到seed中 - 将
nonce值填入seed的后(40-32=8)字节中去,(nonce本身就是uint64类型,是 64 位,对应 8 字节大小),正好把hash和nonce完整的填满了 40 字节的 seed Keccak512加密seed- 从
seed中获取区块头
3.2 从复制的种子开始混合
mixBytes常量= 128,mix的长度为 32,元素为uint32,是 32位,对应为 4 字节大小。所以mix总共大小为 4*32=128 字节大小
mix := make([]uint32, mixBytes/4)
for i := 0; i < len(mix); i++ {
mix[i] = binary.LittleEndian.Uint32(seed[i%16*4:])
}3.3 混合随机数据集节点
temp := make([]uint32, len(mix))//与mix结构相同,长度相同
for i := 0; i < loopAccesses; i++ {
parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows
for j := uint32(0); j < mixBytes/hashBytes; j++ {
copy(temp[j*hashWords:], lookup(2*parent+j))
}
fnvHash(mix, temp)
}3.4 压缩混合
for i := 0; i < len(mix); i += 4 {
mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3])
}
mix = mix[:len(mix)/4]
digest := make([]byte, common.HashLength)
for i, val := range mix {
binary.LittleEndian.PutUint32(digest[i*4:], val)
}
return digest, crypto.Keccak256(append(seed, digest...))最终返回的是digest和digest与seed的哈希;而digest其实就是mix的[]byte形式。在前面Ethash.mine的代码中我们已经看到使用第二个返回值与target变量进行比较,以确定这是否是一个有效的哈希值。
验证pow
挖矿信息的验证有两部分:
- 验证
Header.Difficulty是否正确 - 验证
Header.MixDigest和Header.Nonce是否正确
①:验证Header.Difficulty的代码主要在Ethash.verifyHeader中:
func (ethash *Ethash) verifyHeader(chain consensus.ChainReader, header, parent *types.Header, uncle bool, seal bool) error {
......
expected := ethash.CalcDifficulty(chain, header.Time.Uint64(), parent)
if expected.Cmp(header.Difficulty) != 0 {
return fmt.Errorf("invalid difficulty: have %v, want %v", header.Difficulty, expected)
}
}通过区块高度和时间差作为参数来计算Difficulty值,然后与待验证的区块的Header.Difficulty字段进行比较,如果相等则认为是正确的。
②:MixDigest和Nonce的验证主要是在Header.verifySeal中:
验证的方式:使用Header.Nonce和头部哈希通过hashimoto重新计算一遍MixDigest和result哈希值,并且验证的节点是不需要dataset数据的。
总结&参考
https://github.com/blockchainGuide
公众号:区块链技术栈 (推荐哦)
https://eth.wiki/concepts/ethash/design-rationale
https://eth.wiki/concepts/ethash/dag
https://www.vijaypradeep.com/blog/2017-04-28-ethereums-memory-hardness-explained/
区块链技术网。
- 发表于 2021-02-27 10:34
- 阅读 ( 715 )
- 学分 ( 14 )
- 分类:以太坊






 — POS与POW-DAG缩略图")

评论