Filecoin 二阶段测试(3) – 异构集群测试
 – 异构集群测试插图")
 – 异构集群测试插图1")
 – 异构集群测试插图2")
 – 异构集群测试插图3")
 – 异构集群测试插图4")
 – 异构集群测试插图5")
 – 异构集群测试插图6")
 – 异构集群测试插图7")
 – 异构集群测试插图8")
 – 异构集群测试插图9")
 – 异构集群测试插图10")
 – 异构集群测试插图11")
有人喜欢花 3 天时间完成产品,然后花一年的时候去搞定客户; 而我们却更愿意花 2 年的时间打磨产品,然后花 10 分钟打动客户。
系列导航: [Filecoin 二阶段测试(1) - 小试牛刀](https://learnblockchain.cn/article/1191 "Filecoin 二阶段测试(1) - 小试牛刀") [Filecoin 二阶段测试(2) - AMD CPU 的胜利](https://learnblockchain.cn/article/1193 "Filecoin 二阶段测试(2) - AMD CPU 的胜利") [Filecoin 二阶段测试(3) - 异构集群测试](https://learnblockchain.cn/article/1226) --- 本文是关于 Filecoin 二阶段测试的最后一篇博文。今天给大家分享一下我们近期在测试网验证过的异构集群挖矿方案。 先大概说下我们的集群架构,本次测试总共投入了 9 台机器,角色分配如下: > Miner(C2 + WinPoSt) x 1 + AMD Worker(P1) x 4 + Intel Worker(P2) x 4 ## 1. 测试环境 * 操作系统:Ubuntu-18.04LTS * 测试网络:Filecoin TestNet Master 分支网络(非 interopnet 网络) * Lotus 版本:0.4.0+git.596ed330 * 机器数量:9 * 存储方案:Ceph + Raid0 + Raid5 本次测试我们投入了各种不同的 CPU 型号,各种系统配置也都优化了。测试机器的具体配置如下: ### 1.1 Miner(C2 + WinPoSt) 配置 > * CPU: Intel E5-2683 V4 x 2 * RAM: 256GB + 128GB Swap * 存储:Ceph 存储集群 * 系统盘:128GB SSD x 1 * 高速缓冲盘:2TB NVME x 1 * 万兆网:万兆网口 x 2 * GPU: 2080Ti x 1 Miner 之所以插入了 2 张 GPU 是因为我的 C2 是配置在 Miner 上执行的。 目前 C2 已经可以是多 GPU 并行执行了,下面是我在 C2 运行时候截的图。 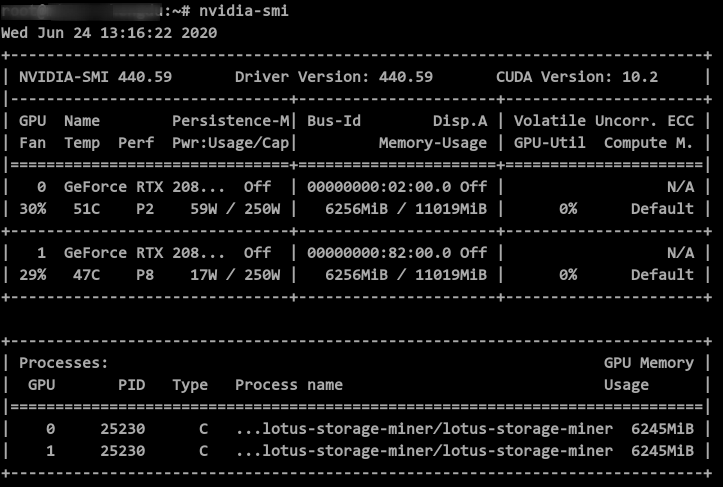 ### 1.2. Worker(P1) 配置 x 4 #### Worker1 > * CPU: AMD 3950x * RAM: 128GB + 128GB Swap * 存储:8TB企业硬盘 x 2 * 系统盘:128GB x 1 * 万兆网:万兆网口 x 1 #### Worker2 > * CPU: AMD 3960x * RAM: 256GB + 128GB Swap * 存储:8TB企业硬盘 x 2 * 系统盘:128GB x 1 * 万兆网:万兆网口 x 1 #### Worker3 > * CPU: AMD 3970x * RAM: 256GB + 128GB Swap * 存储:8TB企业硬盘 x 2 * 系统盘:128GB x 1 * 万兆网:万兆网口 x 1 #### Worker2 > * CPU: AMD 7402 x 2 * RAM: 256GB + 128GB Swap * 存储:8TB企业硬盘 x 2 * 系统盘:128GB x 1 * 万兆网:万兆网口 x 1 ### 1.3 Worker(P2) 配置 x 4 > * CPU: Intel E5-2683 V4 x 2 * RAM: 192GB + 128GB Swap * 存储:8TB企业硬盘 x 2 * 系统盘:128GB SSD x 1 * 高速缓冲盘:1TB NVME x 1 * 万兆网:万兆网口 x 1 * GPU: 2080Ti x 1 ## 2. 集群搭建 本次集群搭建还是使用我们自主研发的 [GammaOS](http://gamma.xjxh.pro/),目前产品已经慢慢趋于完善,点几下鼠标就可以完成整个集群的搭建了。 这里给大家演示一下,由于写本文时我们自己的集群已经搭建好了,重写卸载安装的话,会影响数据的。我们这里给大家演示怎么搭建一个新的小集群,虽然是小集群,但是对于 `GammaOS` 来说搭建大集群和小集群工作量上是没有什么区别的。 (1)安装并启动 `Lotus` 应用(**后面都是 GIF 动图,比较大[2M/张],流量不足者慎入!!!**):  (2)通过 ssh 登录到 Miner 节点,创建钱包和矿工 ```bash gamma_lotus wallet new bls t3rslakvn3kg4y3g2kmgj6pu2rszydinfn4uh5fhnfa4k6wol5oychtkdpjkrqsqs3q54tndmmg7fq42diyqdq ``` 得到钱包地址以后,到官方的水龙头页面去创建矿工。[https://faucet.testnet.filecoin.io/miner.html](https://faucet.testnet.filecoin.io/miner.html) 选择扇区大小(默认 32GB),点击创建就 OK 了。 > 注意:Gamma 重写了 lotus 命令,使用 gamma_lotus 命令替代,下面的 lotus-storage-miner 和 lotus-seal-worker 命令也是一样。 (3)安装并启动 `lotus-storage-miner` :  **注意,在启动 Miner 之前,你需要先手动初始化矿工,目前这一步还没有做到自动化**。 把刚刚水龙头返回的初始化脚本执行就好了,记得需要添加复制证明参数目录的环境变量。 ```bash FIL_PROOFS_PARAMETER_CACHE=/gamma/filecoin-proof-parameters gamma_lotus-storage-miner init --actor=t0117997 --owner=t3rslakvn3kg4y3g2kmgj6pu2rszydinfn4uh5fhnfa4k6wol5oychtkdpjkrqsqs3q54tndmmg7fq42diyqdq ``` (3)安装 `lotus-seal-worker`  (4)启动 Worker: 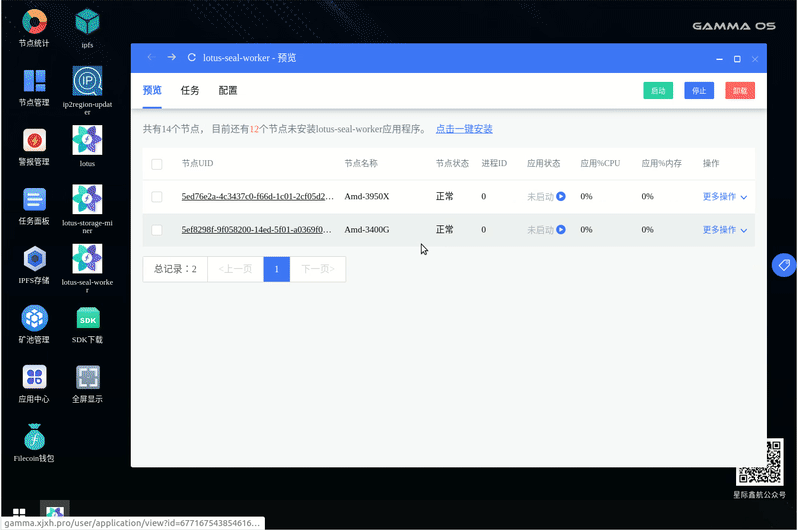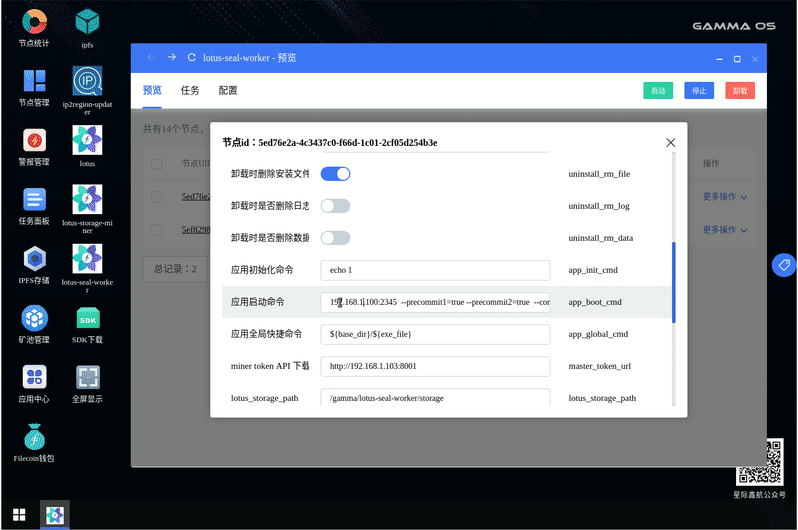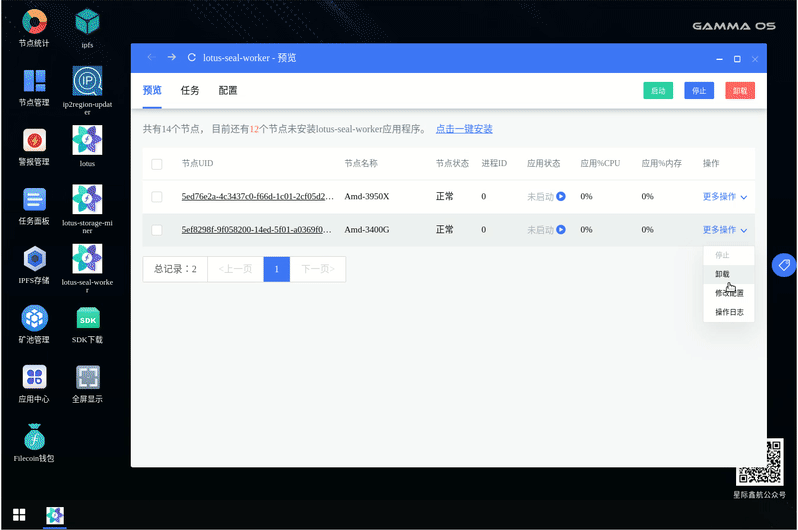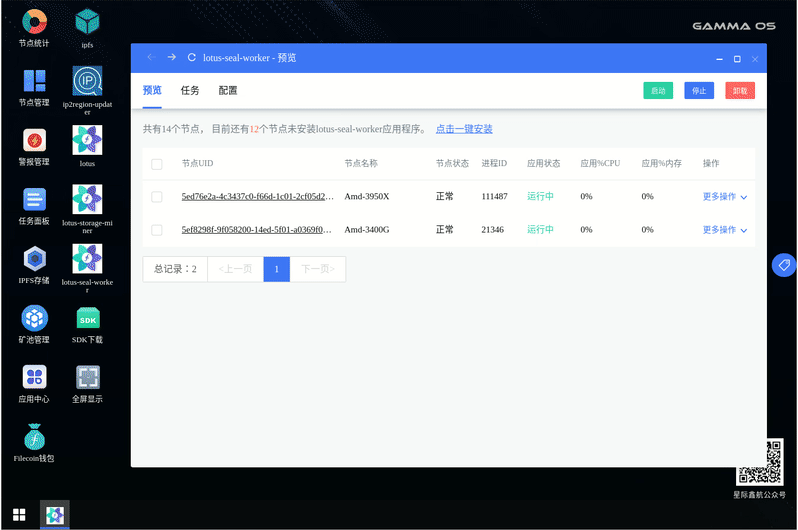 批量启动多个 Worker: 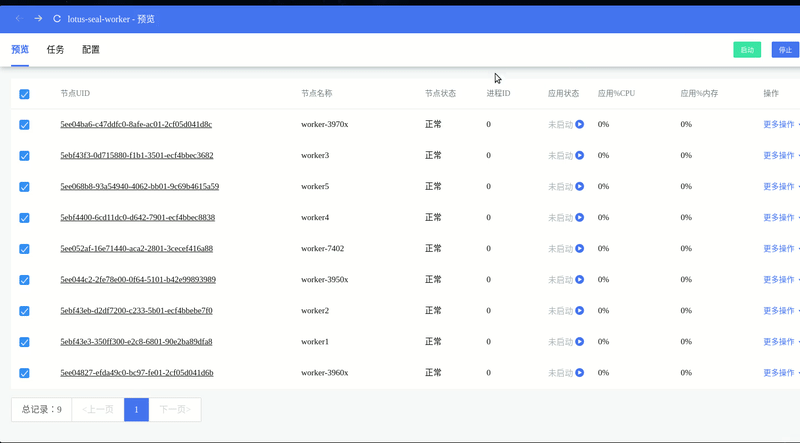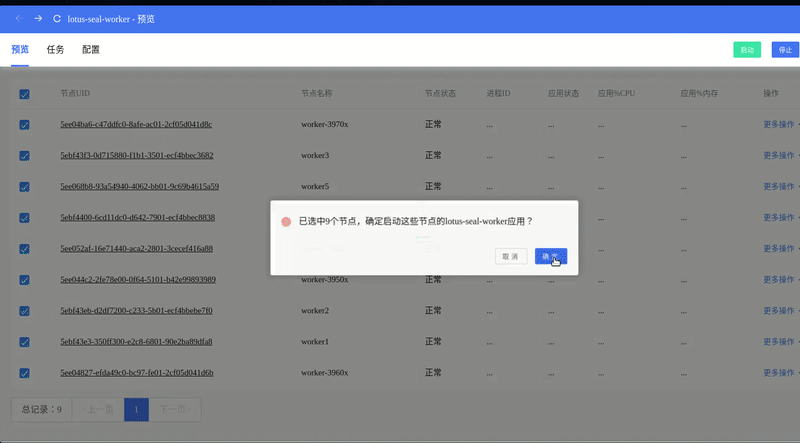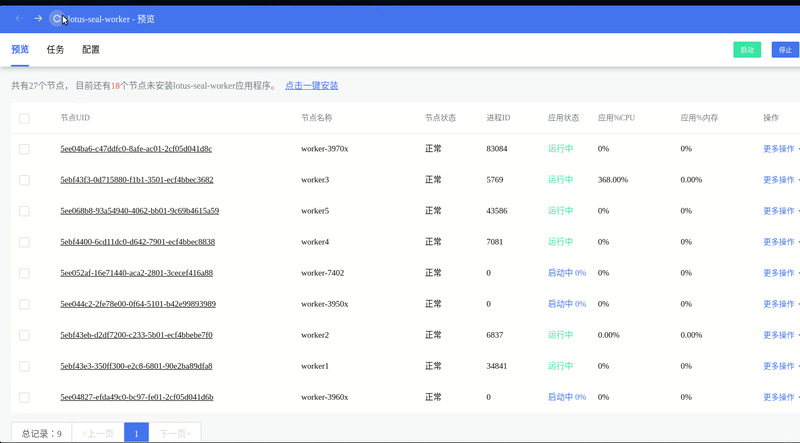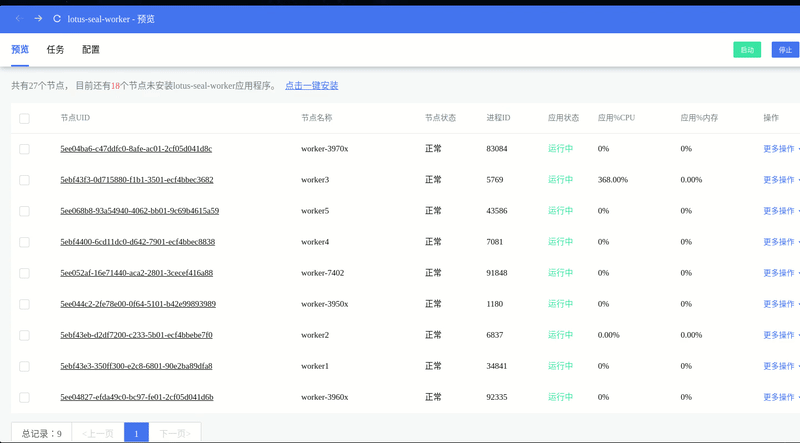 我们登录到 `miner-company` 验证一下 worker 是否已经正常启动了。 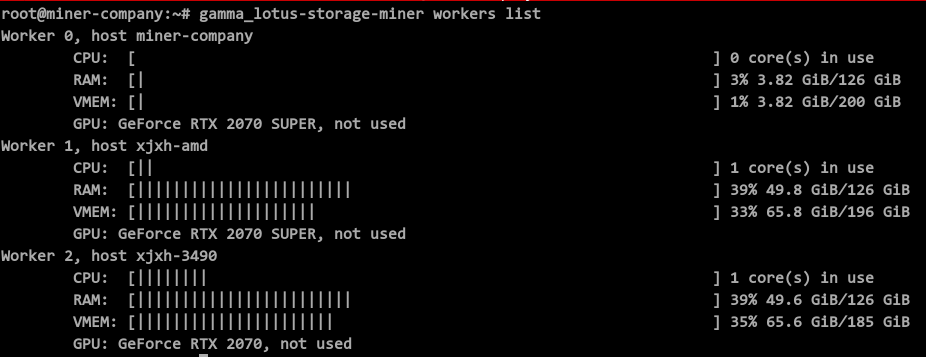 当前集群已经稳定运行 5 天了,目前一切正常,除了有段时间关机调整机器配置掉了 3 个扇区的算力以外,后面就再也没有掉过算力。 目前 Miner Info 如下图所示: 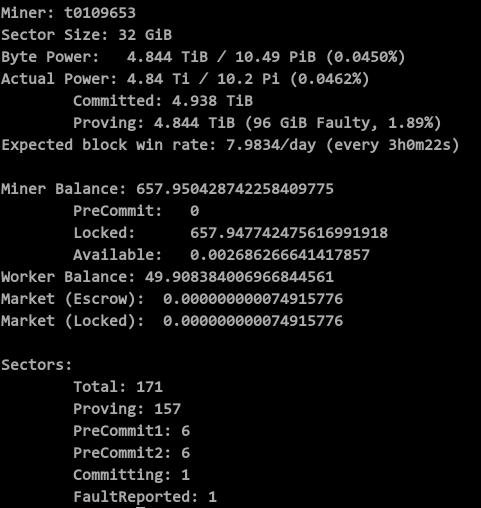 ## 3. 踩坑记录 这次在整个测试过程中踩了太多的坑,有的就是一个小细节的问题,就导致了整个集群的效率降低了10%。不过这也是我们测试的目的,我们只关注测试本身,不关注数据和排名。尽可能的把主网上线后可能出现的问题,都给模拟了一遍, 然后找出对应的解决方案。比如我们会故意把 Miner 停机 30min-2h 看是否会掉算力,怎样配置掉算力的概率小一些?以及掉算力如何尝试恢复... 反正就是各种做死的这折腾。 这里给大家分享踩过的两个小坑: ### 3.1 Swap 修改之后需要重启 Miner/Worker 进程。 在增加或者减少 Swap 空间之后要记得重启 Miner/Worker,Swap 和内存大小是在程序启动时候获取,然后一直缓存,而不是每次在分配任务的时候临时判断,所以修改 Swap 之后必须重启程序才能生效。 ### 3.2 Miner AddPieces 或许会成为大矿工测试的瓶颈 扇区增多的时候,主节点的 addPieces 速度跟不上,目前测试数据是每个扇区需要 6.5min-10min. 下面是 AddPieces 实测数据: #### Intel E5-2683 V4 + 128GB RAM + 2TB NVME * 1 sector : 11min12s * 3 sectors: 13min10s * 8 sectors: 40min5s #### AMD 3950x + 128GB RAM + 1 TB NVME * 1 sector : 9min7s * 3 sectors: 10min56s * 10 sectors: 45min17s > 测试数据基本表明,单机一次性添加 3 sector 是比较好的方案,另外 AddPieces 非常耗费 CPU 资源,如果 Miner CPU 资源长期被被占用,会严重影响 PoSt 和出块。 假如你打算参与竞争那 400w FIL 测试奖励的话,你的目标应该是在21天内完成 PB 级的数据密封。按 1PB 算的话,那么你 Miner 需要每天完成 1800 多个 sector 的 AddPieces,这目前来说这个难度很高,甚至是不现实的。 这个问题有两个解决方案: 第一, 配置更高的CPU(如128C)以及更快的磁盘(如 Intel 的 M2 高速盘),这是下策。 第二, 更好的办法是修改源码,把 AddPieces 直接放到 Worker 去做,这样一个可以分流,每台 Worker 所需要完成的 AddPieces 的 Sector 数量大大减少,其次是减少了 32GB 的数据传输。 一个好消息是官方已经在讨论把方案二实现在官方代码了,这对不会改源码的同学来说,无疑是一个福音。不过我问了 `Why` 是否能在 TestNet 上线之前完成,但是还没有回复。 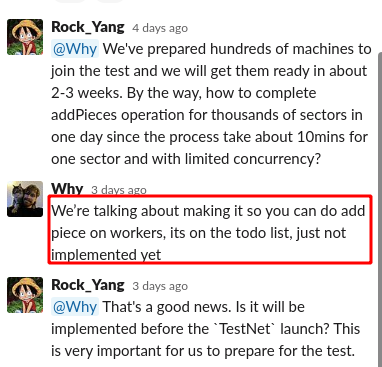 希望在 `TestNet` 上线之前官方能够把这个功能能够被实现吧。毕竟自己改代码是容易,但是维护起来真的挺麻烦的。 ### 3.3 使用 ssh 取代远程桌面控制软件 我们成都机房在测试的过程中出现大量节点被攻击的情况,几乎整个局域网的机器都停摆,每个节点都运行了一个叫 `playstation` 的程序, 所有机器的 CPU 资源几乎都被耗尽,ssh 连接都非常卡顿。该程序杀掉之后又自动重启,卸载之后又重装,破坏性极大。 截了两张图给大家体验一下: 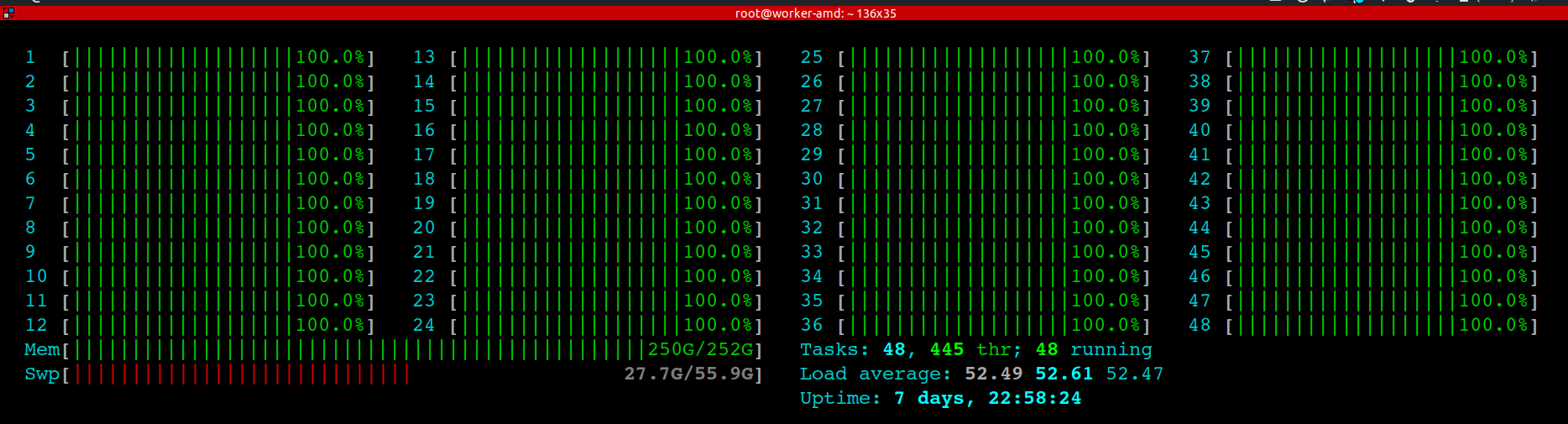 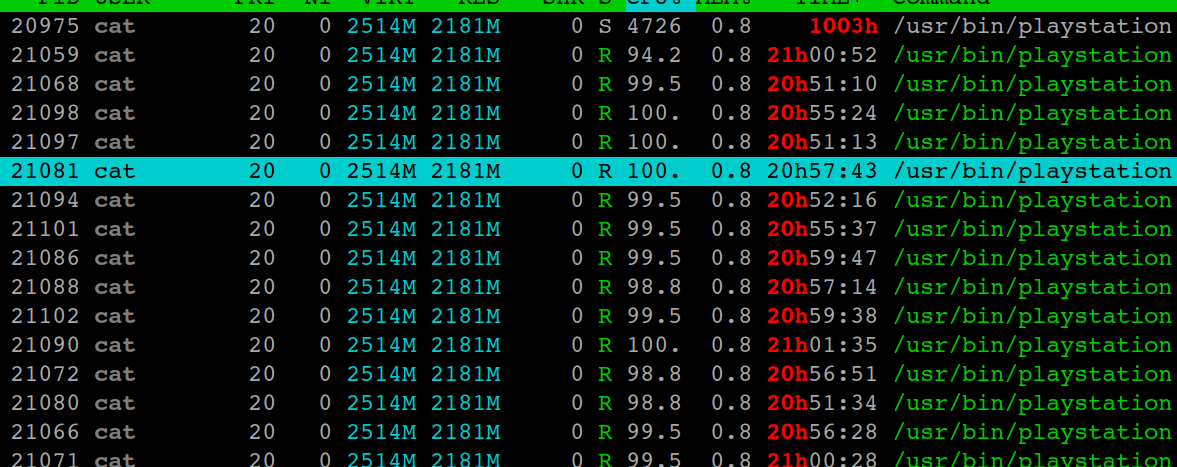 经过分析后,发现居然是远程桌面软件 TeamView 的问题,可能是 TeamView 的漏洞被人利用了,解决方法是卸载 TeamView, 然后再删除集群中所有机器上 playstation 应用程序,重启机器后便恢复了正常。 > 温馨提示: 如果机房有公网 IP 的话,建议直接使用 ssh 连接机器,而且建议使用私钥取代密码登录。 如果机房没有公网 IP 的话,也建议借用别的公网IP(如阿里云)进行内网穿透或者代理来实现远程 ssh 连接。 > 本文首发于:[`小一辈无产阶级码农`](http://www.r9it.com/) 原文链接:http://www.r9it.com/20200626/filecoin-phase2-test3.html
系列导航: Filecoin 二阶段测试(1) - 小试牛刀 Filecoin 二阶段测试(2) - AMD CPU 的胜利 Filecoin 二阶段测试(3) - 异构集群测试
本文是关于 Filecoin 二阶段测试的最后一篇博文。今天给大家分享一下我们近期在测试网验证过的异构集群挖矿方案。
先大概说下我们的集群架构,本次测试总共投入了 9 台机器,角色分配如下:
Miner(C2 + WinPoSt) x 1 + AMD Worker(P1) x 4 + Intel Worker(P2) x 4
1. 测试环境
- 操作系统:Ubuntu-18.04LTS
- 测试网络:Filecoin TestNet Master 分支网络(非 interopnet 网络)
- Lotus 版本:0.4.0+git.596ed330
- 机器数量:9
- 存储方案:Ceph + Raid0 + Raid5
本次测试我们投入了各种不同的 CPU 型号,各种系统配置也都优化了。测试机器的具体配置如下:
1.1 Miner(C2 + WinPoSt) 配置
- CPU: Intel E5-2683 V4 x 2
- RAM: 256GB + 128GB Swap
- 存储:Ceph 存储集群
- 系统盘:128GB SSD x 1
- 高速缓冲盘:2TB NVME x 1
- 万兆网:万兆网口 x 2
- GPU: 2080Ti x 1
Miner 之所以插入了 2 张 GPU 是因为我的 C2 是配置在 Miner 上执行的。
目前 C2 已经可以是多 GPU 并行执行了,下面是我在 C2 运行时候截的图。
1.2. Worker(P1) 配置 x 4
Worker1
- CPU: AMD 3950x
- RAM: 128GB + 128GB Swap
- 存储:8TB企业硬盘 x 2
- 系统盘:128GB x 1
- 万兆网:万兆网口 x 1
Worker2
- CPU: AMD 3960x
- RAM: 256GB + 128GB Swap
- 存储:8TB企业硬盘 x 2
- 系统盘:128GB x 1
- 万兆网:万兆网口 x 1
Worker3
- CPU: AMD 3970x
- RAM: 256GB + 128GB Swap
- 存储:8TB企业硬盘 x 2
- 系统盘:128GB x 1
- 万兆网:万兆网口 x 1
Worker2
- CPU: AMD 7402 x 2
- RAM: 256GB + 128GB Swap
- 存储:8TB企业硬盘 x 2
- 系统盘:128GB x 1
- 万兆网:万兆网口 x 1
1.3 Worker(P2) 配置 x 4
- CPU: Intel E5-2683 V4 x 2
- RAM: 192GB + 128GB Swap
- 存储:8TB企业硬盘 x 2
- 系统盘:128GB SSD x 1
- 高速缓冲盘:1TB NVME x 1
- 万兆网:万兆网口 x 1
- GPU: 2080Ti x 1
2. 集群搭建
本次集群搭建还是使用我们自主研发的 GammaOS,目前产品已经慢慢趋于完善,点几下鼠标就可以完成整个集群的搭建了。
这里给大家演示一下,由于写本文时我们自己的集群已经搭建好了,重写卸载安装的话,会影响数据的。我们这里给大家演示怎么搭建一个新的小集群,虽然是小集群,但是对于 GammaOS 来说搭建大集群和小集群工作量上是没有什么区别的。
(1)安装并启动 Lotus 应用(后面都是 GIF 动图,比较大[2M/张],流量不足者慎入!!!):
(2)通过 ssh 登录到 Miner 节点,创建钱包和矿工
gamma_lotus wallet new bls
t3rslakvn3kg4y3g2kmgj6pu2rszydinfn4uh5fhnfa4k6wol5oychtkdpjkrqsqs3q54tndmmg7fq42diyqdq得到钱包地址以后,到官方的水龙头页面去创建矿工。https://faucet.testnet.filecoin.io/miner.html
选择扇区大小(默认 32GB),点击创建就 OK 了。
注意:Gamma 重写了 lotus 命令,使用 gamma_lotus 命令替代,下面的 lotus-storage-miner 和 lotus-seal-worker 命令也是一样。
(3)安装并启动 lotus-storage-miner :
注意,在启动 Miner 之前,你需要先手动初始化矿工,目前这一步还没有做到自动化。
把刚刚水龙头返回的初始化脚本执行就好了,记得需要添加复制证明参数目录的环境变量。
FIL_PROOFS_PARAMETER_CACHE=/gamma/filecoin-proof-parameters gamma_lotus-storage-miner init --actor=t0117997 --owner=t3rslakvn3kg4y3g2kmgj6pu2rszydinfn4uh5fhnfa4k6wol5oychtkdpjkrqsqs3q54tndmmg7fq42diyqdq(3)安装 lotus-seal-worker
(4)启动 Worker:
批量启动多个 Worker:
我们登录到 miner-company 验证一下 worker 是否已经正常启动了。
当前集群已经稳定运行 5 天了,目前一切正常,除了有段时间关机调整机器配置掉了 3 个扇区的算力以外,后面就再也没有掉过算力。
目前 Miner Info 如下图所示:
3. 踩坑记录
这次在整个测试过程中踩了太多的坑,有的就是一个小细节的问题,就导致了整个集群的效率降低了10%。不过这也是我们测试的目的,我们只关注测试本身,不关注数据和排名。尽可能的把主网上线后可能出现的问题,都给模拟了一遍, 然后找出对应的解决方案。比如我们会故意把 Miner 停机 30min-2h 看是否会掉算力,怎样配置掉算力的概率小一些?以及掉算力如何尝试恢复... 反正就是各种做死的这折腾。
这里给大家分享踩过的两个小坑:
3.1 Swap 修改之后需要重启 Miner/Worker 进程。
在增加或者减少 Swap 空间之后要记得重启 Miner/Worker,Swap 和内存大小是在程序启动时候获取,然后一直缓存,而不是每次在分配任务的时候临时判断,所以修改 Swap 之后必须重启程序才能生效。
3.2 Miner AddPieces 或许会成为大矿工测试的瓶颈
扇区增多的时候,主节点的 addPieces 速度跟不上,目前测试数据是每个扇区需要 6.5min-10min.
下面是 AddPieces 实测数据:
Intel E5-2683 V4 + 128GB RAM + 2TB NVME
- 1 sector : 11min12s
- 3 sectors: 13min10s
- 8 sectors: 40min5s
AMD 3950x + 128GB RAM + 1 TB NVME
- 1 sector : 9min7s
- 3 sectors: 10min56s
- 10 sectors: 45min17s
测试数据基本表明,单机一次性添加 3 sector 是比较好的方案,另外 AddPieces 非常耗费 CPU 资源,如果 Miner CPU 资源长期被被占用,会严重影响 PoSt 和出块。 假如你打算参与竞争那 400w FIL 测试奖励的话,你的目标应该是在21天内完成 PB 级的数据密封。按 1PB 算的话,那么你 Miner 需要每天完成 1800 多个 sector 的 AddPieces,这目前来说这个难度很高,甚至是不现实的。
这个问题有两个解决方案:
第一, 配置更高的CPU(如128C)以及更快的磁盘(如 Intel 的 M2 高速盘),这是下策。
第二, 更好的办法是修改源码,把 AddPieces 直接放到 Worker 去做,这样一个可以分流,每台 Worker 所需要完成的 AddPieces 的 Sector 数量大大减少,其次是减少了 32GB 的数据传输。
一个好消息是官方已经在讨论把方案二实现在官方代码了,这对不会改源码的同学来说,无疑是一个福音。不过我问了 Why 是否能在 TestNet 上线之前完成,但是还没有回复。
希望在 TestNet 上线之前官方能够把这个功能能够被实现吧。毕竟自己改代码是容易,但是维护起来真的挺麻烦的。
3.3 使用 ssh 取代远程桌面控制软件
我们成都机房在测试的过程中出现大量节点被攻击的情况,几乎整个局域网的机器都停摆,每个节点都运行了一个叫 playstation 的程序, 所有机器的 CPU 资源几乎都被耗尽,ssh 连接都非常卡顿。该程序杀掉之后又自动重启,卸载之后又重装,破坏性极大。
截了两张图给大家体验一下:
经过分析后,发现居然是远程桌面软件 TeamView 的问题,可能是 TeamView 的漏洞被人利用了,解决方法是卸载 TeamView, 然后再删除集群中所有机器上 playstation 应用程序,重启机器后便恢复了正常。
温馨提示: 如果机房有公网 IP 的话,建议直接使用 ssh 连接机器,而且建议使用私钥取代密码登录。 如果机房没有公网 IP 的话,也建议借用别的公网IP(如阿里云)进行内网穿透或者代理来实现远程 ssh 连接。
本文首发于:
小一辈无产阶级码农原文链接:http://www.r9it.com/20200626/filecoin-phase2-test3.html
区块链技术网。
- 发表于 2020-07-07 22:52
- 阅读 ( 2198 )
- 学分 ( 125 )
- 分类:FileCoin







评论